Stage de deuxième année
Note importante : Cet article ne présente que l'essentiel. Si vous souhaitez entrer dans les détails techniques et comprendre comment j'ai résolu chaque difficulté, ma documentation complète est disponible ci-dessous.
Migration d'une base de données de mots de passe
Lors de mon arrivée chez Innlog, j'ai dû m'approprier rapidement leurs outils internes. L'entreprise utilisait historiquement TPM comme gestionnaire de mots de passe, mais le service IT avait décidé de migrer vers Vaultwarden, une alternative Open Source conçue en Rust. Pour ça j'ai expérimenté deux solutions, exportation de fichiers CSV, l'API de TPM. J'ai passé beaucoup de temps sur la solution des fichiers CSV car TPM n'exporte qu'en CSV. Le coffre fort TPM qu'utilise Innlog contient 6500 entrées qui sont reparties dans plusieurs projets et pour exporter il faut télécharger tous les projets un par un à la main. J'ai donc du automatisé ce processus avec la librairie Python Playwright qui simule un comportement humain sur un site web et qui faisait donc la manipulation d'exportation à ma place. Avec cette technique j'avançais plutôt bien dans le téléchargement des centaines de fichiers CSV mais le script ne marchait plus à partir du moment ou il trouvait un projet qui a le même nom qu'un précédent même si il se trouve dans une autre branche de projets. À partir de ce moment la je me suis penché sur l'API de TPM pour pouvoir tout récuperer beaucoup plus rapidement et ne pas dépendre d'un script python qui fait des manipulations mais d'un script python qui exécute une commande en boucle jusqu'à la fin des entrées de mots de passe ce qui est plus fiable.
Avec les commandes présentes sur la documentation officielle de TPM, un curl, j'ai pu récupérer des fichiers en .json qui contenait des informations intéressantes :
curl -u <login TPM>:"mdp pour se connecter à TPM" -H 'Content-Type:application/json;
charset=utf-8' -i https://url_du_tpm/index.php/api/v5/passwords/page/1.jsonCe curl la récupère un .json comme ça :
{
"id": 8980,
"name": "",
"project": {
"id": 1418,
"name": "FTP"
},
"notes_snippet": "",
"tags": "",
"access_info": "",
"username": "",
"email": "",
"has_password": true,
"expiry_date": null,
"expiry_status": 0,
"archived": false,
"project_archived": false,
"favorite": false,
"num_files": 0,
"locked": false,
"locking_type": 0,
"external_sharing": false,
"linked": false,
"updated_on": "2026-01-02 12:18:40"
},
Donc dans ces champs
je n’ai pas le mot de passe en clair, cependant j’ai des id qui vont me permettre de
refaire un curl et d’ajouter cet id à l’url avec ça GET /passwords/ID.json
si je reprend mon curl ça va donner quelque chose comme ça avec l’id du fichier ci
dessus
curl -u <login tpm>:"mdp pour se connecter à tpm" -H 'Content-Type:
application/json; charset=utf-8' -i
https://url_tpm/index.php/api/v5/passwords/8980.jsonCe qui va me donner un json comme ça :
{
"id": 8980,
"name": "",
"project": {
"id": 1418,
"name": "FTP"
},
"tags": "",
"access_info": "",
"username": "",
"email": "",
"password": "",
"expiry_date": null,
"expiry_status": 0,
"notes": "",
"custom_field1": null,
"custom_field2": null,
"custom_field3": null,
"custom_field4": null,
"custom_field5": null,
"custom_field6": null,
"custom_field7": null,
"custom_field8": null,
"custom_field9": null,
"custom_field10": null,
"users_permissions": null,
"groups_permissions": null,
"parents": [
1180,
1217,
1218,
1412,
1418
],
"user_permission": {
"id": 30,
"label": "Manage"
},
"archived": false,
"project_archived": false,
"favorite": false,
"num_files": 0,
"locked": false,
"locking_type": 0,
"locking_request_notify": 0,
"external_sharing": false,
"external_url": null,
"linked": false,
"source_password_id": 0,
"managed_by": {
"id": 2,
"username": "",
"email_address": "",
"name": "",
"role": "IT"
},
"created_on": "2025-12-31 10:53:29",
"created_by": {
"id": 2,
"username": "",
"email_address": "",
"name": "",
"role": "IT"
},
"updated_on": "2026-01-02 12:18:40",
"updated_by": {
"id": 2,
"username": "",
"email_address": "",
"name": "",
"role": "IT"
}
}cette fois ci avec un champs password qui contient bien le mot de passe en clair Donc pour l’instant j’en suis rendu là, il faudra que je montre mes avancements au responsable IT qui revient lundi pour voir la meilleure solution possible car c’est une manipulation beaucoup plus compliquée que prévu.
Au début de ma deuxième semaine, j'ai essayé d'importer un CSV de test qui venait de KeePassXC et ça marchait il fallait donc que je trouve un moyen de convertir les json que je récuperais de l'API en CSV compatible KeePassXC. J'ai donc fais une checklist des modifications que devait faire le script avec le json.

J'ai donc commencé par le script qui change les "numéros ID" en "mots ID" pour me retrouver avec des .json comme ça, le problème que j'ai eu en faisant ça c'est que certains projets sont vides et n'ont donc pas d'ID et ne peuvent pas conséquent par être changer en mot.
"parents": [
"INNLOG - Commun",
"TESFRI",
"1218",
"1458",
"FTP"
],Comme solution j'ai donc pensé à faire un script qui récupère lui tous les projets avec leurs noms et leurs ID et qui a comme condition "si je ne trouve pas un nom correspondant à l’ID par exemple 1218 je vais voir dans l’autre fichier .json si je le trouve et si je le trouve je viens le remettre dans le fichier .json de base." Et seulement maintenant je peux passer à la conversion passant du .json au CSV KeePassXC
Après avoir passé le fichier json en CSV, j'avais encore un problème, Vaultwarden a une protection anti-DoS qui fait que je ne peux pas importer un fichier CSV avec des milliers de lignes. Il fallait donc parsé (séparé) le fichier en plusieurs fichiers. À la fin de la journée j'ai finis avec tous ces scripts et ces fichiers CSV que je pouvais enfin importé dans Vaultwarden.
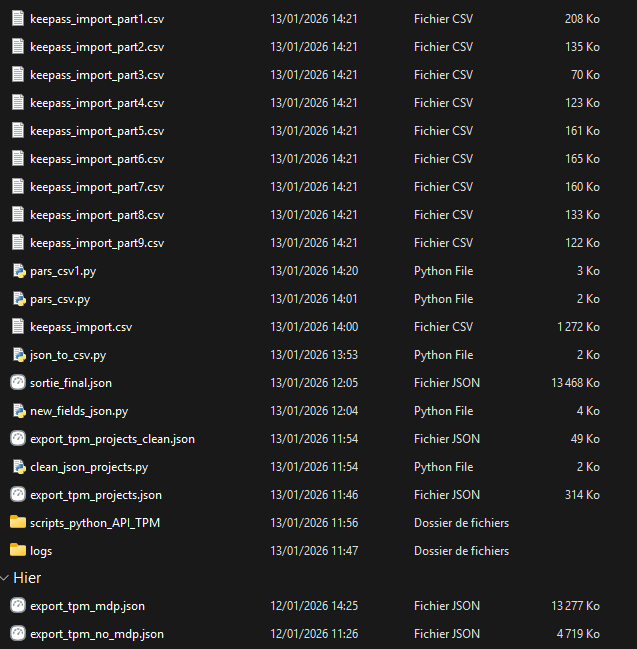
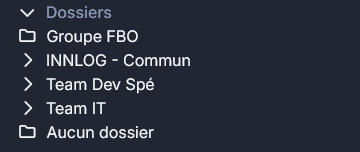
Ensuite dans Vaultwarden il faut créer une organisation pour pouvoir gérer des utilisateurs, des groupes etc.

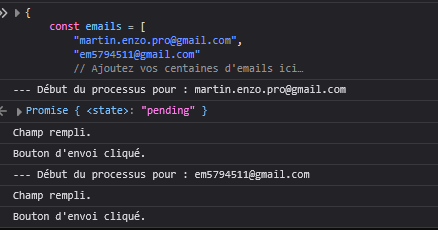
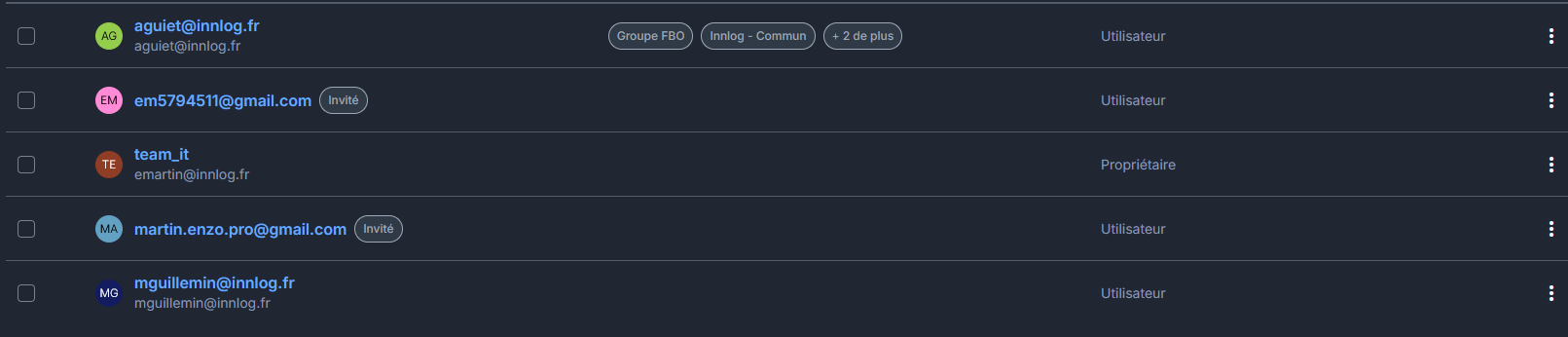
Pour inviter des personnes à utiliser le coffre Innlog il faut les inviter par mails encore une fois un par un, il a donc fallu automatisé ça aussi. Au début j'ai pensé à concaténer plusieurs adresses mails avec des séparateurs comme {} ou , mais ça ne marchait pas. Après ça, j'ai donner à une IA, l'attributs html qui servait à ouvrir un fenêtre modal en JavaScript et l'attribut du bouton "Envoyer" et avec ça j'ai eu un morceau de code JavaScript à balancer dans la console en faisant F12 qui automatisait l'envoie de mail à toutes les adresses mails présentes dans le tableau du morceau de code. Et j'ai essayé avec deux adresses mails qui m'appartiennent pour tester.
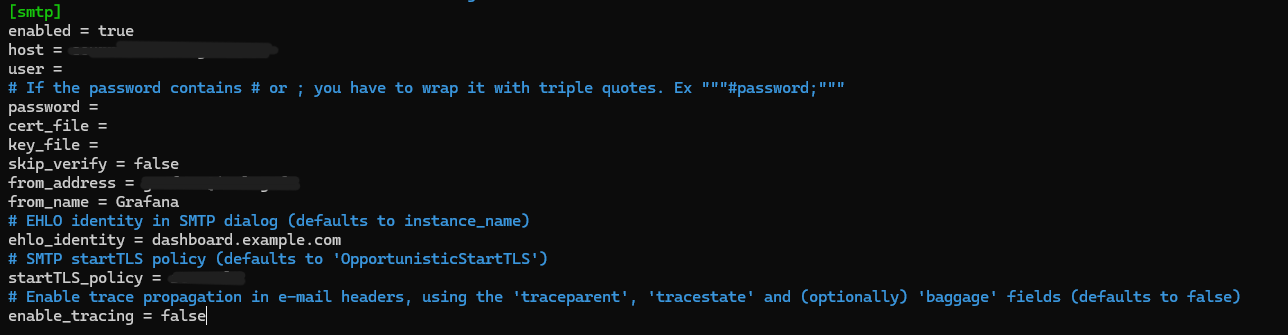
Il fallait aussi configurer un serveur SMTP sur Vaultwarden


Mise en place d'une infrastructure wifi pour un client
À partir de jeudi, la migration vers Vaultwarden étant terminé, j'ai été affecté à une autre mission; mettre en place une infrastructure wifi pour l'un
des gros clients de Innlog. Ce client ayant une infrastructure vieillissante diffusant encore sous le protocole WEP.
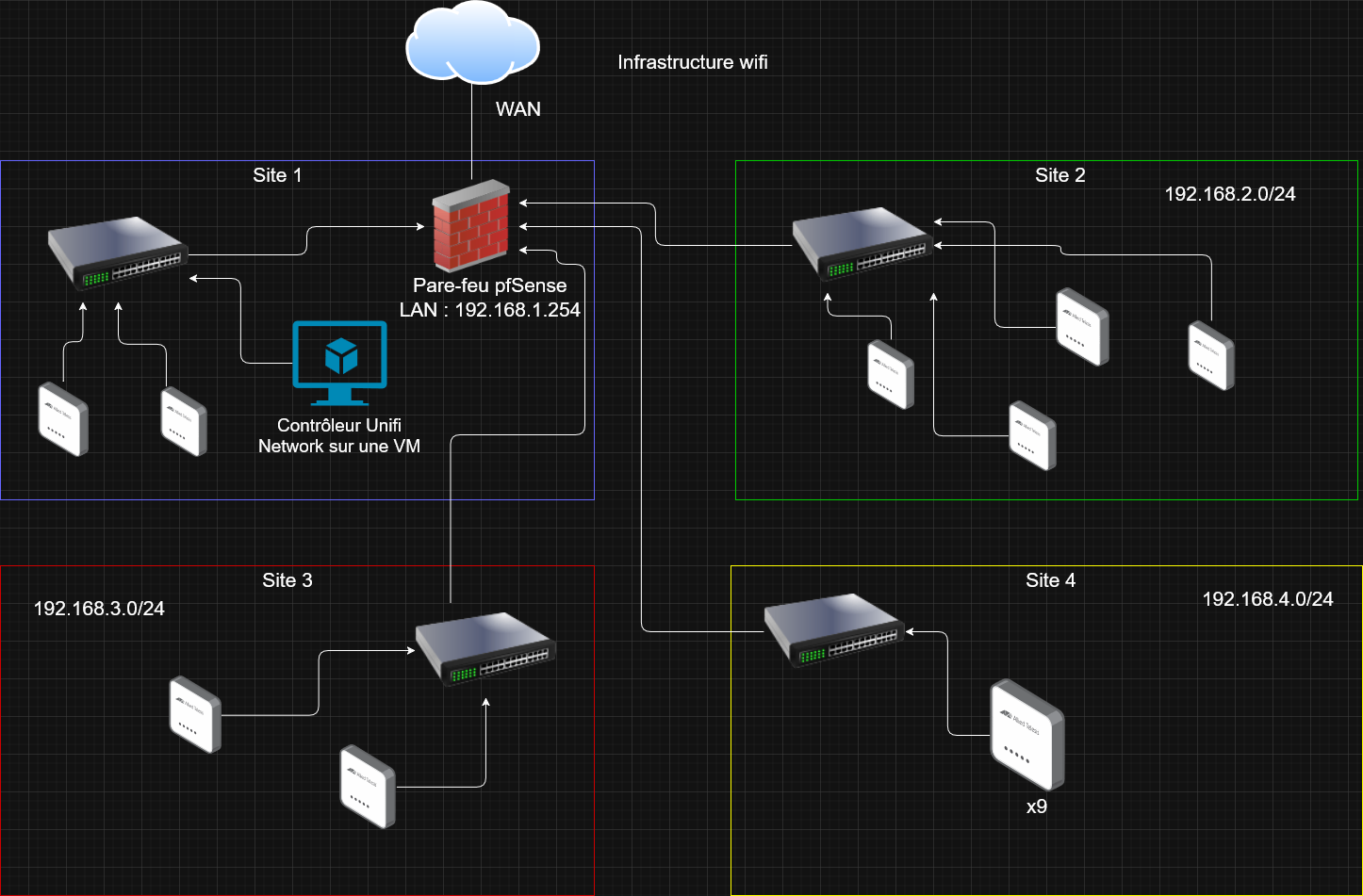
Cette nouvelle infrastructure contient 4 switchs Cisco (pour 4 sites distincts) et 17 bornes Unifi U7 outdoor, pour le lab que j'ai mis en place, je n'ai qu'un
seul pare-feu pfSense pour les 4 sites mais dans la réalité, chaque site aura son pare-feu attribuer. Je me suis donc permis de faire le schéma de l'infrastructure sur draw.io
Le contrôleur Unifi étant une machine virtuelle, les bornes devaient toutes remontées sur le contrôleur, les plus faciles étaient celles du premier site car elles sont dans le même réseau que le pare-feu mais ensuite, celles qui étaient dans les autres réseux je devais me connecter en SSH et faire une commande spécifique pour envoyer une invitation au contrôleur pour que qu'il adopte la borne. Je récupère les adresses IP des bornes dans les bails DHCP que distribue le pfSense.
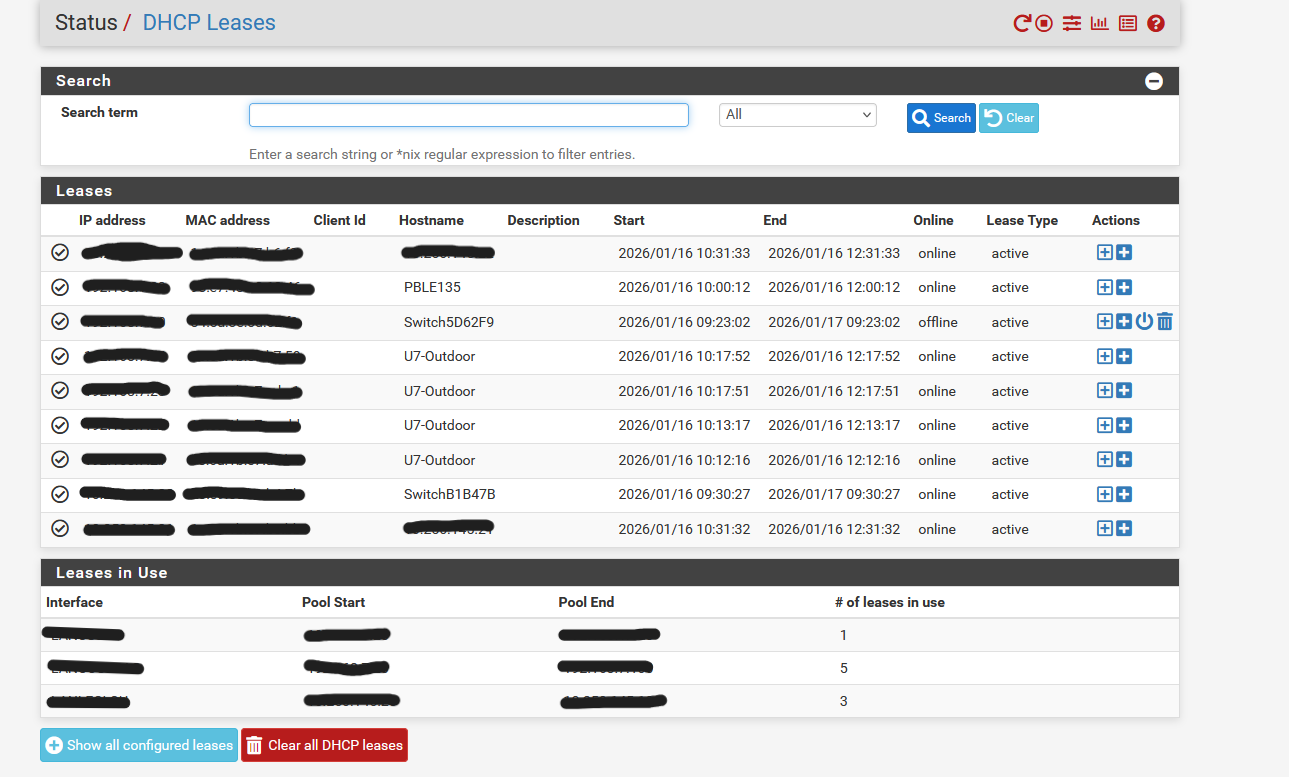
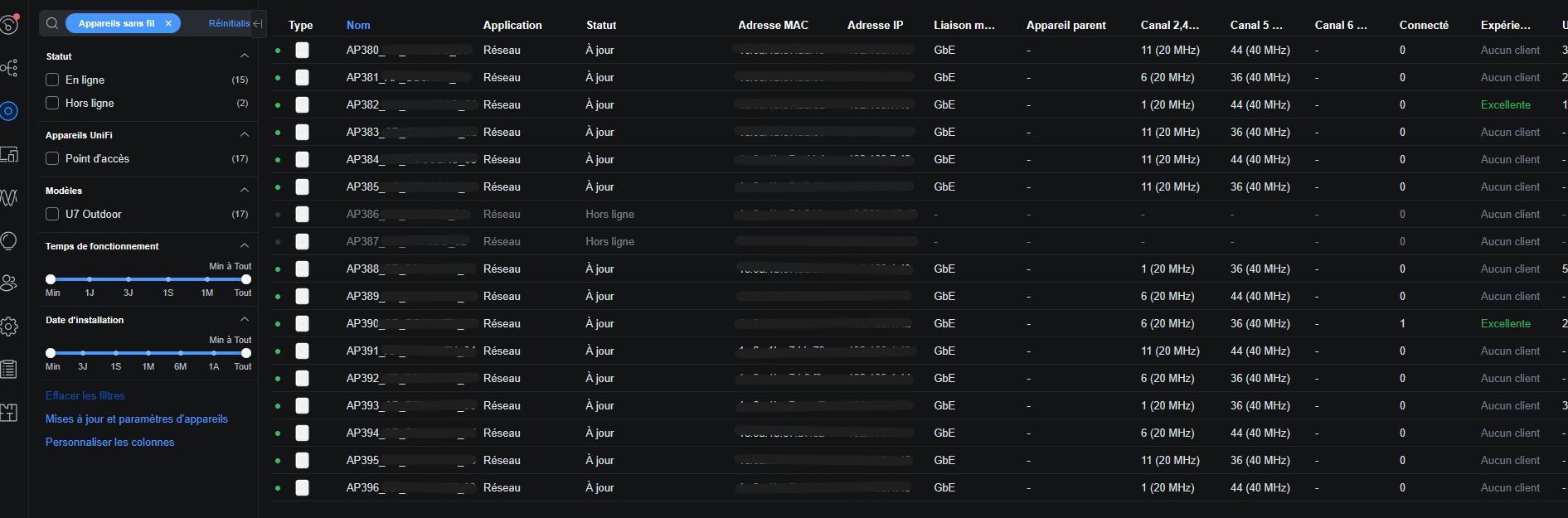
Ça donne ça à la fin, deux bornes étant hors ligne car le pfSense n’a pas assez de ports pour connecter tous les switchs.
Le lundi de la troisième semaine, Anthony le responsable IT à qui j'avais donné un accès pour tester le Vaultwarden a rencontré un problème. En effet il avait accès aux différentes entrées présentes dans le coffre de l'organisation Innlog mais quand il cliquait sur une entrée il ne voyait pas l'URL. J'ai donc regardé et il s'avère que par défaut les utilisateurs invités ont le droit d'Afficher les éléments, hors pour voir les URL dans les entrées, il faut avec les droits Afficher les éléments, les mots de passe cachés.
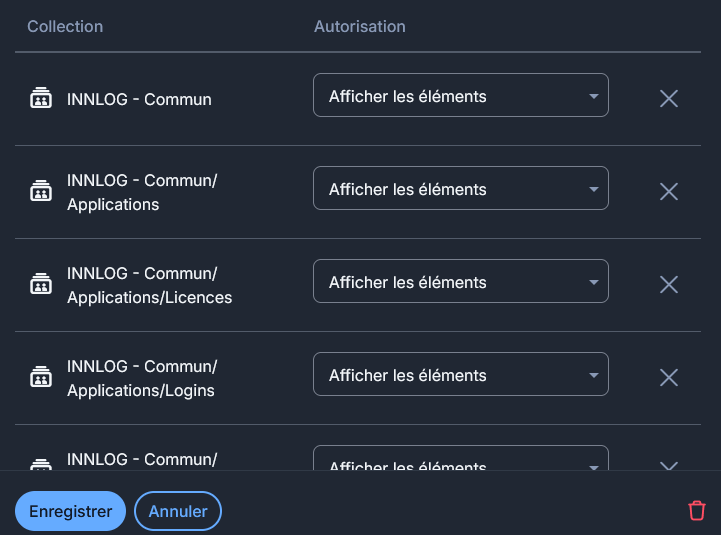
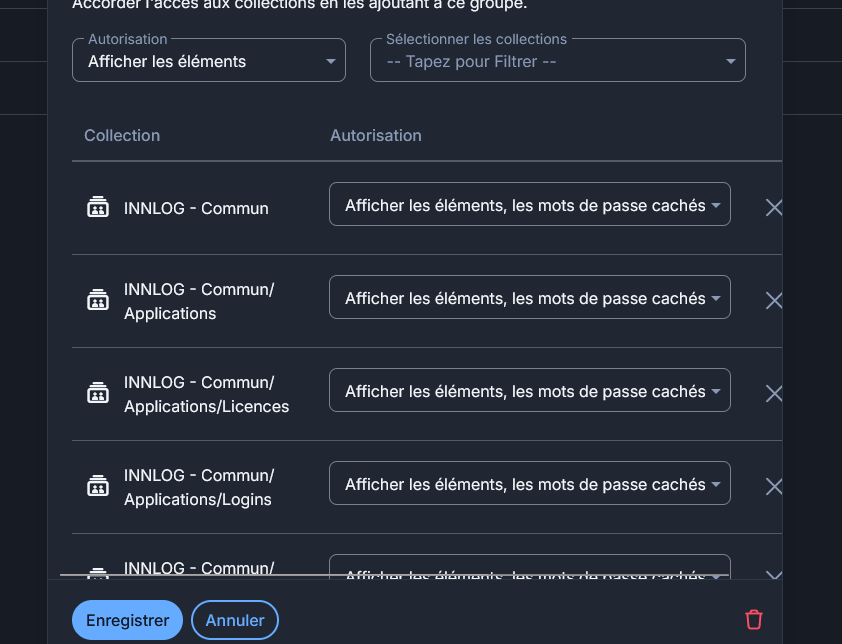
J'ai donc dû automatisé le changement des permissions étant donné qu'il y a plus de 500 dossiers sur lesquels il faut changer ces permissions. Toujours avec un bout de JavaScript que je lance dans la console du navigateur.
Ce qui fait que les permissions ressemblaient toutes à ça à la fin du script.
Ensuite j'ai décidé de faire une documentation sur l'utilisation des scripts Python et JavaScript pour la migration des mots de passe de TPM vers Vaultwarden. En interne Innlog possède un WikiJS qui est un projet Open Source qui peut être auto-hébergé et qui sert à stocké des documentation pour l'ensemble du service sous forme de .md (markdown)
La procédure est disponible ici et sera présente en annexe de ma documentation complète du stage.
Arrivé au jeudi, on avait demandé des plans d'un des sites du client pour lequel j'avais dû faire leur infrastructure wifi pour que dans le logiciel du contrôleur je puisse faire une HeatMap c'est-à-dire un plan avec l'emplacement des bornes wifi pour voir la couverture qu'elles ont.
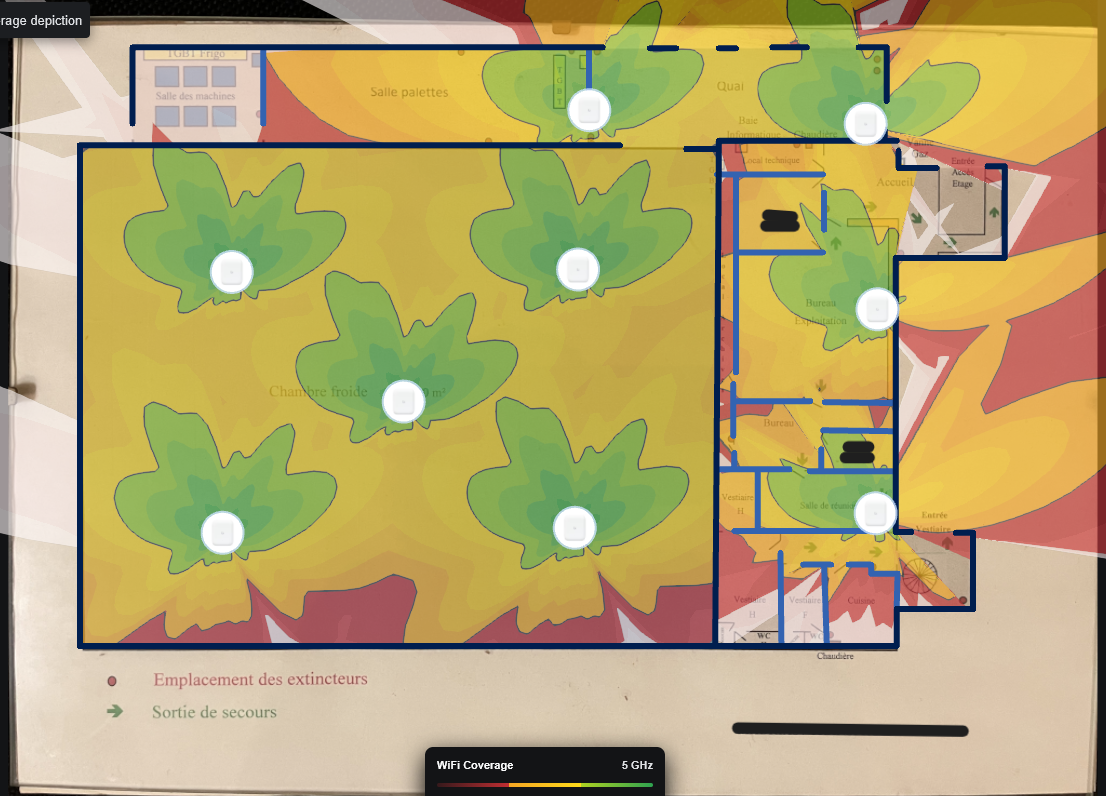
Une fois la HeatMap terminée, on a envoyé le fichier de configuration du contrôleur au client pour qu'il puisse l'importer dans la VM que eux on mis en place.

Déploiement d'une stack Grafana, Alloy et Loki
En fin de semaine, une nouvelle mission m’a été confiée : mettre en place un serveur de centralisation des logs. Dans un premier temps, nous avions envisagé d’utiliser Graylog afin de centraliser les remontées de logs. J’ai donc commencé à me documenter sur la technologie ainsi que sur son installation, mais je me suis rapidement heurté à un problème. Graylog repose sur MongoDB comme moteur de base de données, or à partir de la version 5.0, ce moteur nécessite l’utilisation d’instructions AVX. Cela implique l’utilisation d’un processeur capable de gérer ce type d’instructions. Cependant, ma VM fonctionne sur un hyperviseur équipé d’un processeur d’architecture Nehalem, qui ne supporte pas ces instructions. L’installation de Graylog était donc physiquement impossible.
On a donc décidé de déployer une stack Grafana, Alloy et Loki.
Petit détail de la stack :
-
Grafana
Grafana est l'interface web, elle va utiliser Loki comme source de données pour pouvoir créer des dashboard et faire remonter les logs correctement.
-
Alloy
Alloy est un agent qui va s'occuper d'envoyer les logs d'une machine sur l'API de Loki, il va également s'occuper de parser correctement les logs.
-
Loki
Loki est l'outil qui va stocker les logs, une fois qu'Alloy aura envoyé les logs à Loki il va les stocker et devenir une source de données pour Grafana
J'ai d'abord commencé par installer tout ce dont j'avais besoin ;
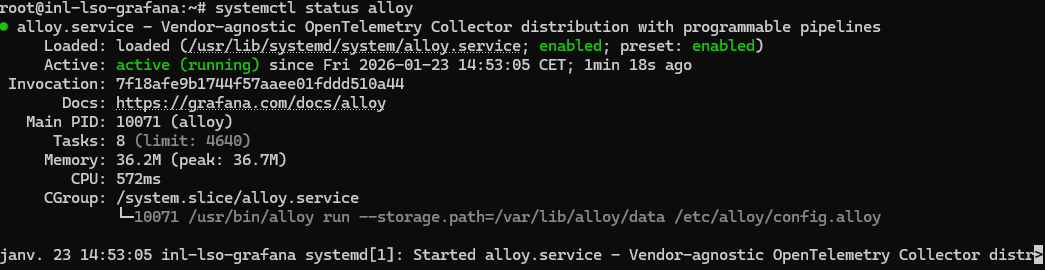
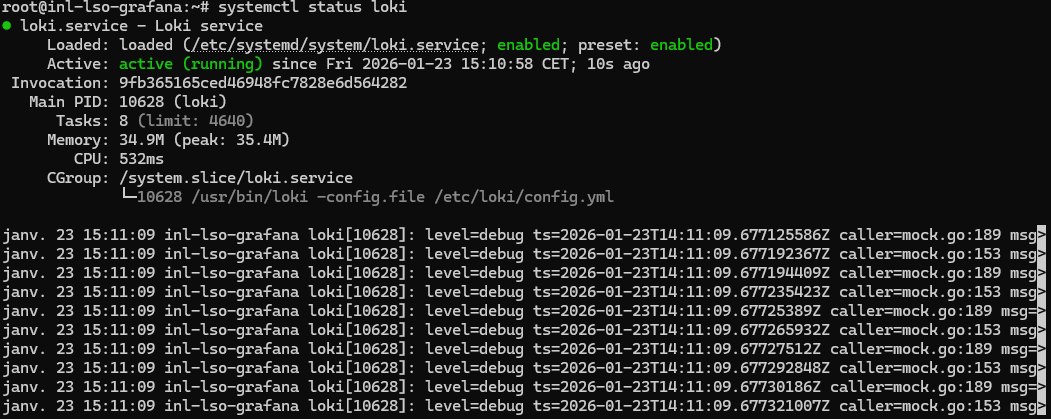
Une fois que tous les outils étaient installés, j'ai dû aller modifier le fichier de configuration d'Alloy config.alloy afin de mettre les bon blocs pour dans un premier temps afficher les logs SSH dans Grafana.
logging {
level = "info"
}
loki.source.journal "systemd" {
forward_to = [loki.write.default.receiver]
labels = {
job = "journald",
host = "<ip de l’hôte>",
}
}
loki.write "default" {
endpoint {
url = "http://127.0.0.1:3100/loki/api/v1/push"
}
}
logs SSH :
loki.relabel "journal_filter" {
forward_to = [loki.write.default.receiver]
rule {
source_labels = ["__journal__systemd_unit"]
regex = "ssh.service"
target_label = "job"
replacement = "ssh"
}
}Après avoir modifié le fichier de config il faut ajouter Loki en tant que source de données dans Grafana pour pouvoir faire remonter les logs SSH.
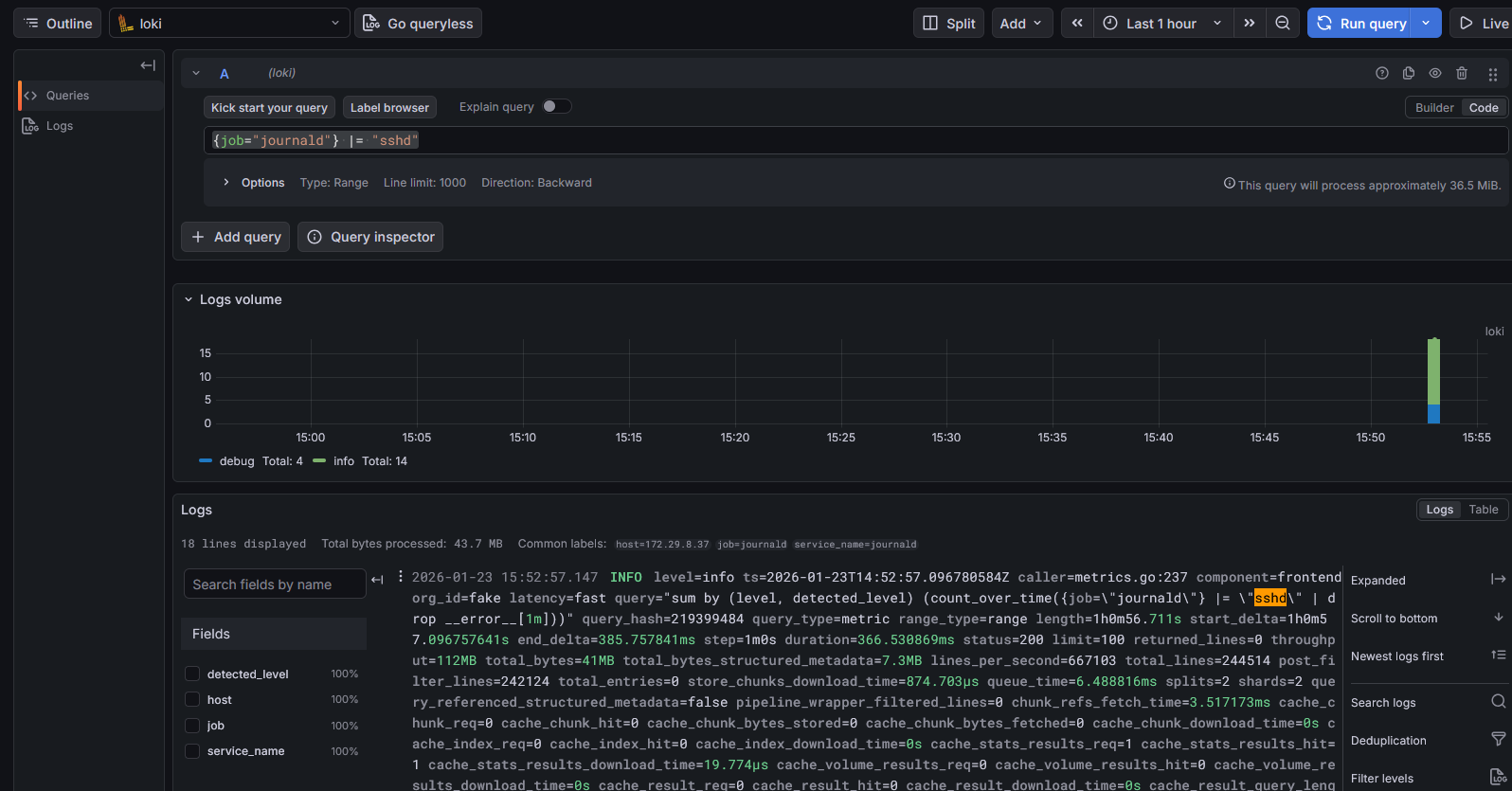
Après ça j'ai décidé d'installer Prometheus pour faire remonter des métriques systèmes comme la charge CPU, la RAM, la bande passante etc.
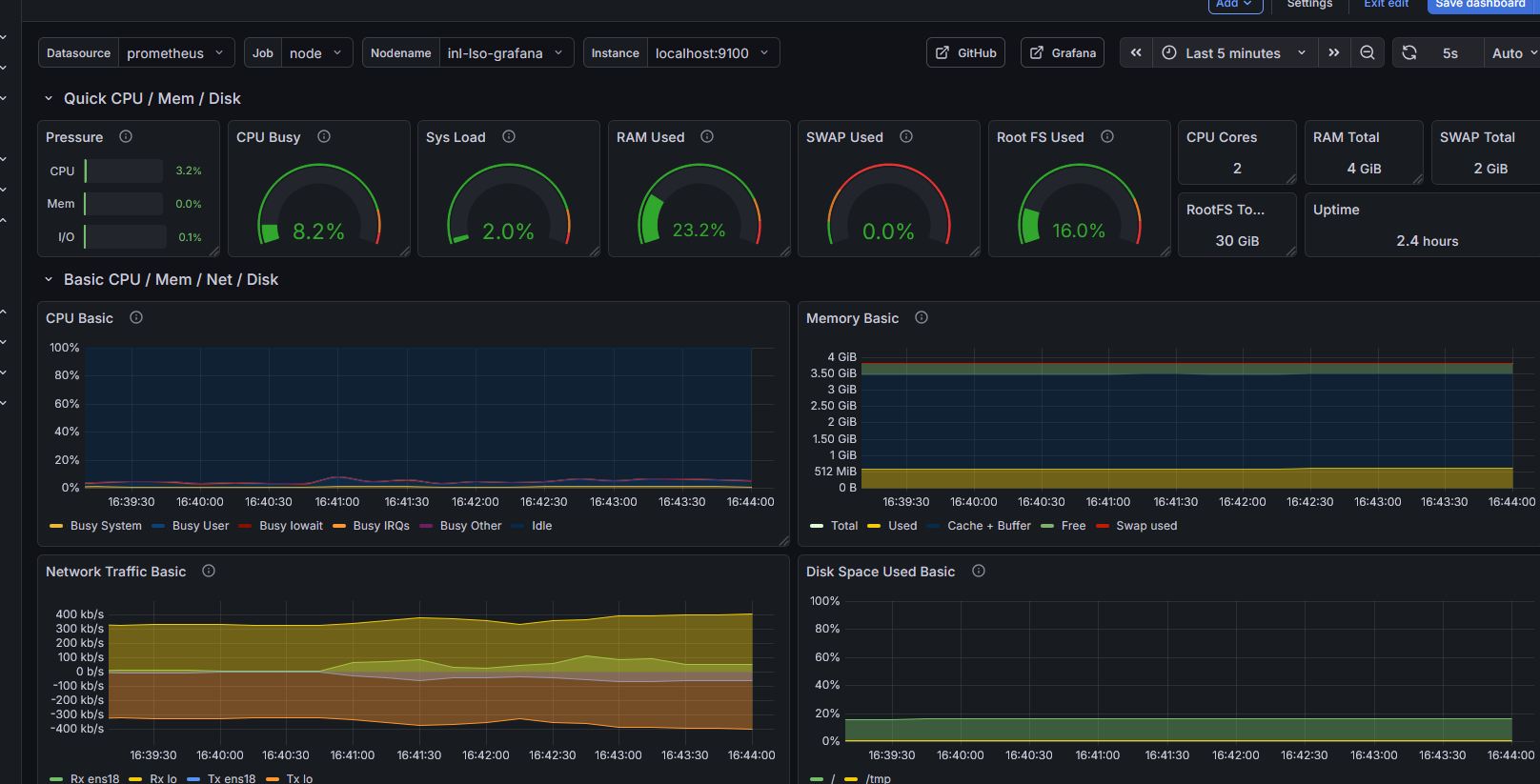
Enfin, il fallait trouver les bons LogQL pour bien parser les logs SSH pour que ce soit plus lisible et faire remonter les informations que l'on veut, une sorte de filtre.
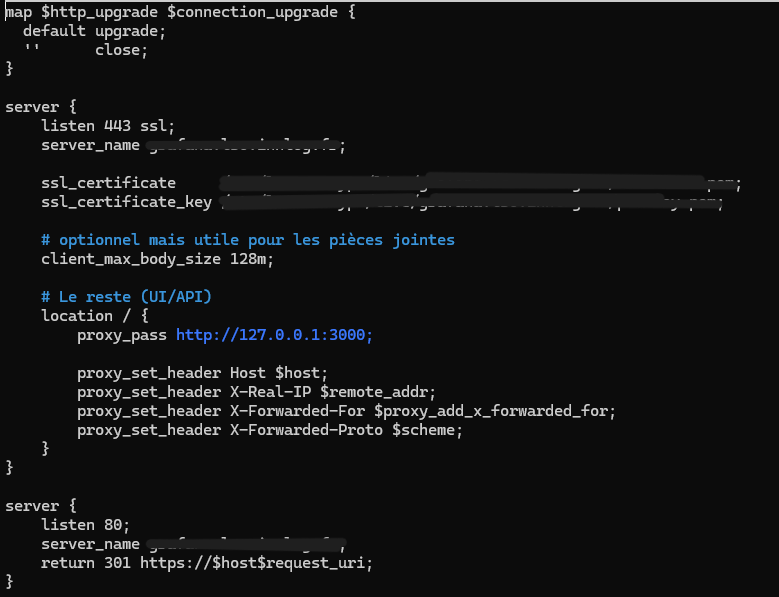
Pour ma stack Grafana, Alloy, Loki, je l'ai mise tout d'abord en HTTPS et avec un nom de domaine dernière un reverse proxy NGINX étant donné que c'est quelque chose qui servira à l'entreprise à l'avenir, il fallait donc quelque chose de stable.

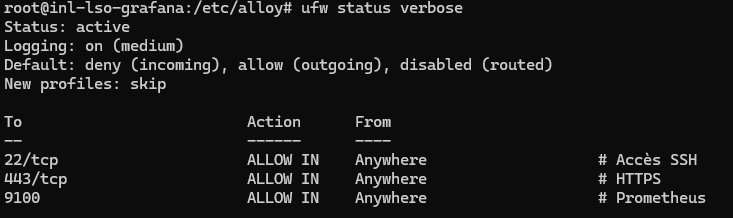
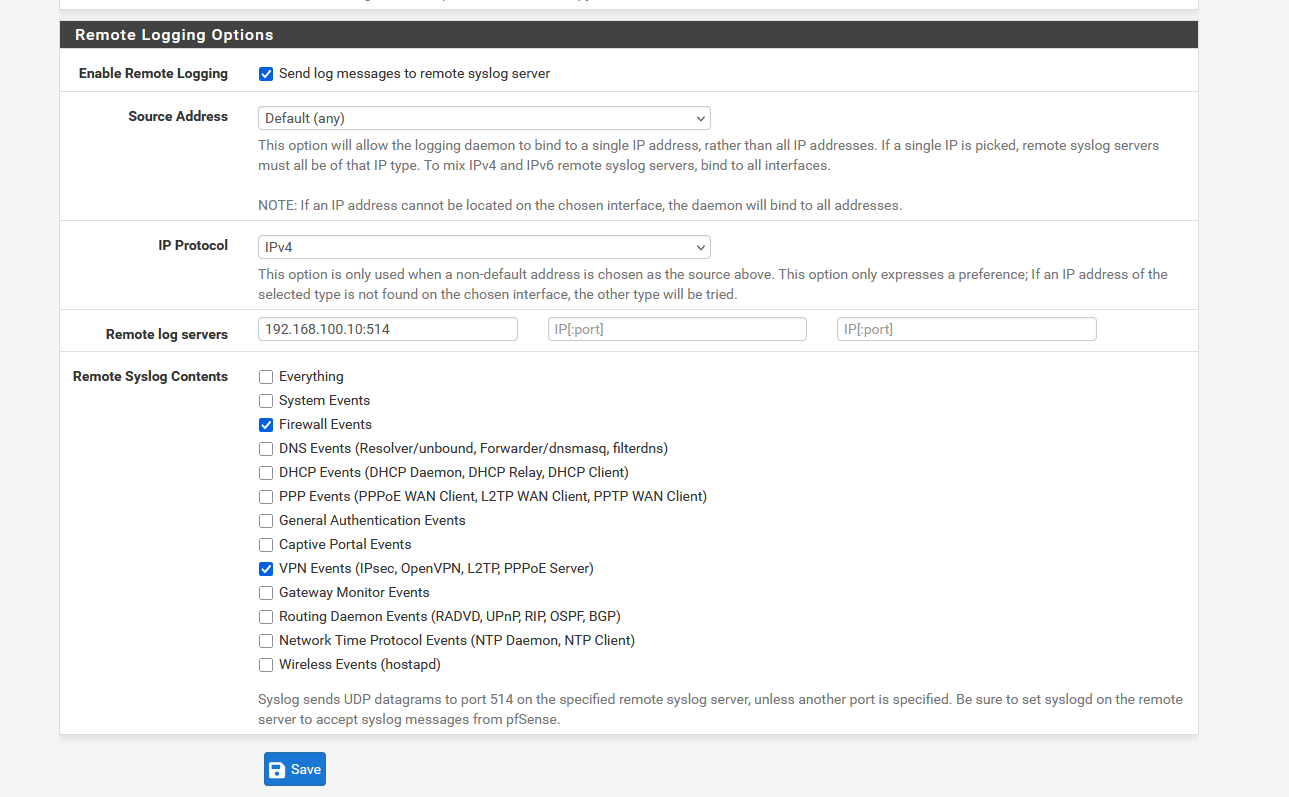
Ensuite il fallait que je mette un pare-feu UFW pour à l'avenir avoir des logs des flux qu'UFW bloque.
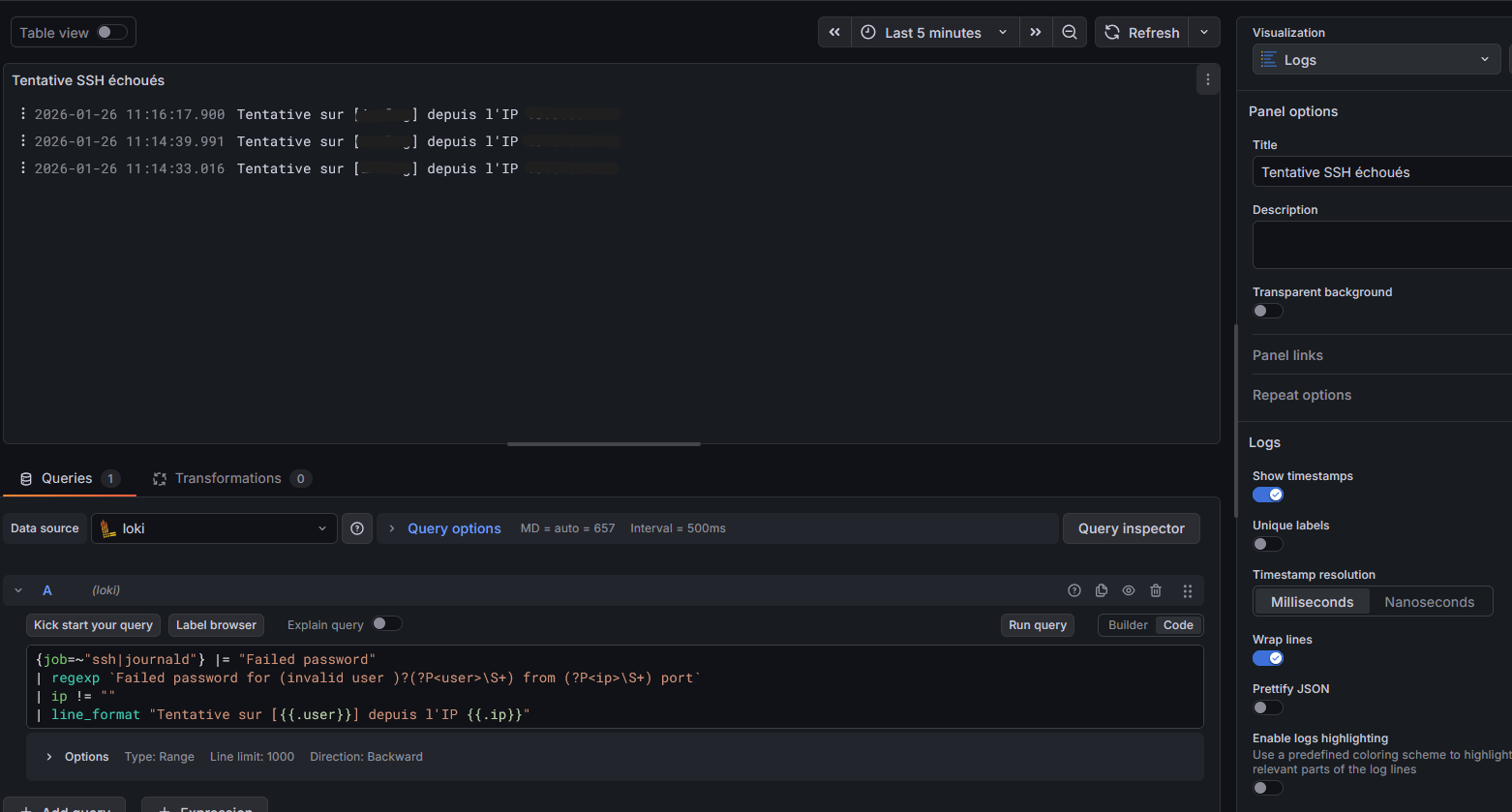
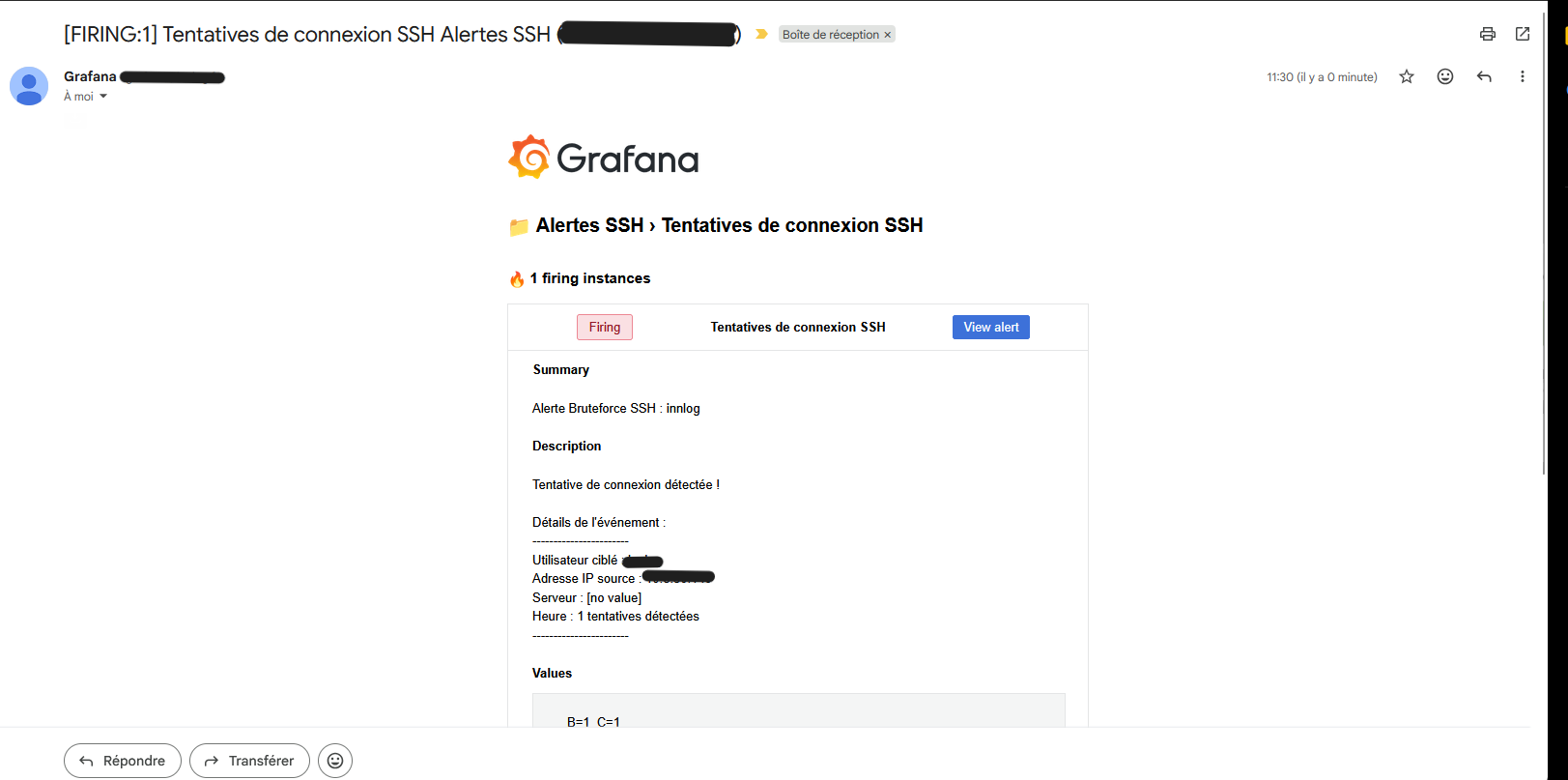
Ensuite j'ai refait mon logQL pour les Logs SSH afin que Grafana me remonte les tentatives de connexions ratées et qu'il utilise un agent SMTP pour m'envoyer un mail lors d'une tentatives de connexion.
Des logs UFW qui ressemblaient à ça :
Les ALLOW et les BLOCK


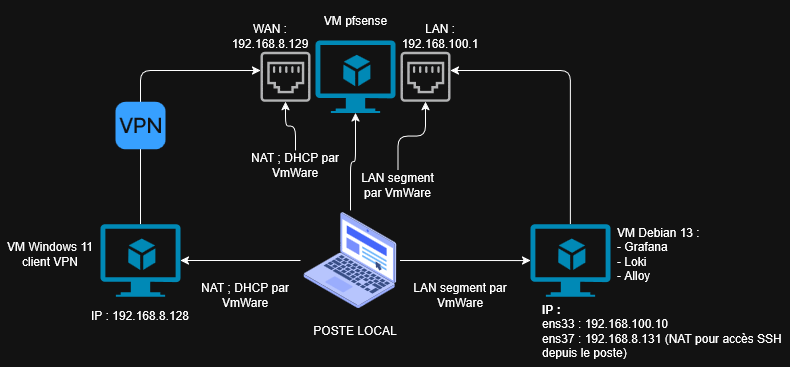
En milieu de semaine je suis attaqué à la remonter de logs d'un pfsense. Pour ça j'ai mis en place un lab en utilisant des VM en locale, une cliente sous Windows 11 qui sera connectée en VPN à une autre VM sous pfsense et une troisième VM sous Debian 13 qui elle jouera le rôle de la machine Grafana.
J'ai fait un schéma réseau sur draw.io pour mon infra de lab histoire que ce soit plus clair pour le debug réseau.
En fin de semaine j'ai préparé le terrain pour accueillir les logs du pfsense. J'ai d'abord dû installer rsyslog pour pouvoir
recevoir les logs provenant du pare-feu et dans deuxième temps j'ai fait un fichier de configuration dans /etc/rsyslog.d
pour dire à rsyslog que si les logs proviennent de 192.168.100.1 qui est mon interface LAN
et bien de créer le fichier de log /var/log/pfsense.log

La prochaine étape était de monter le tunnel VPN sur le pfsense, par défaut pfsense utilise OpenVPN pour les tunnels mais des plugins permettent notamment d'utiliser WireGuard. D'envoyer le fichier de configuration VPN sur le client Windows 11 et voir dans un premier temps si des logs remontaient dans le pfsense.
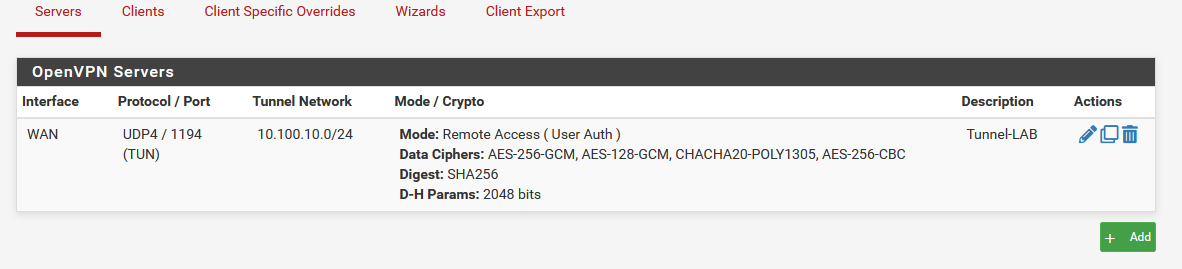
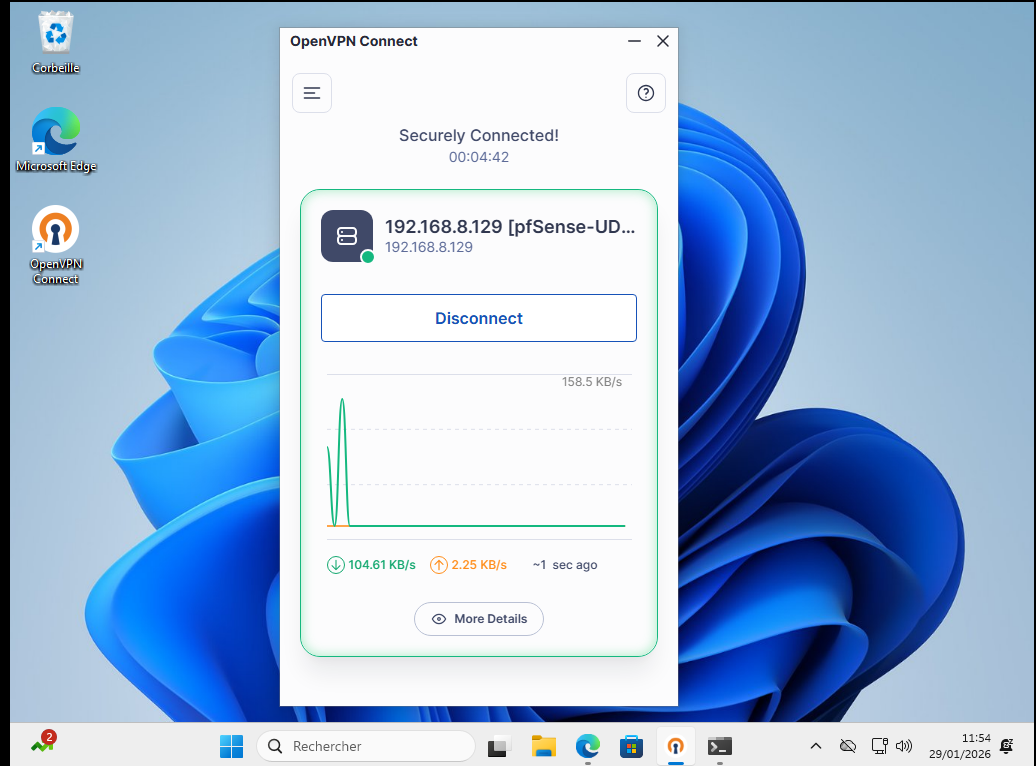

On voit que les logs remontent bien dans le pfsense, il faut maintenant le configurer afin qu'il envoie les logs à la machine Linux.
Et ensuite bien aller vérifier si le fichier de log est crée sur la machine et que les logs se trouvent bien dedans.

L'étape suivante est maintenant d'utiliser Alloy et Loki pour faire remonter ce fichier de log dans Grafana et les afficher comme on le souhaite avec les bons LogQL.
Pour la suite de la stack Grafana, j'ai fait remonter label pfsense dans Grafana ce qui m'a permis d'afficher les premier logs du pfsense dans un format pas très lisible mais qu'il faudra filtrer et parser avec les bon LogQL
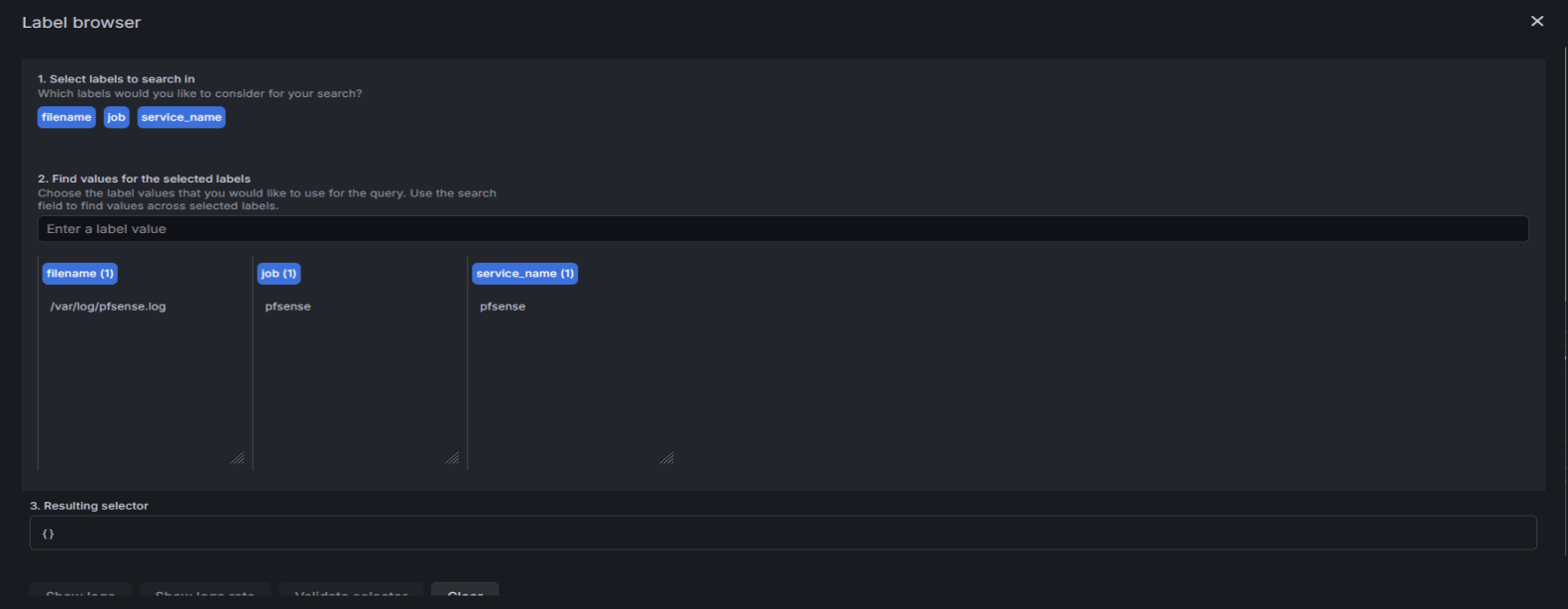
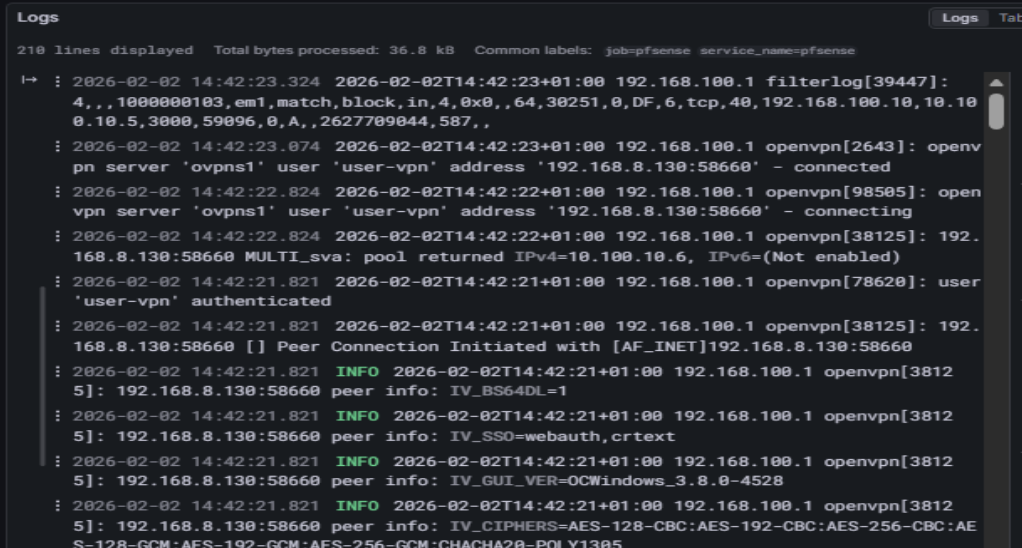
Ensuite avec les bons LogQL on arrive à faire appaître des logs comme ceci, ici en l'occurence les flux bloqués et les connexions OpenVPN.


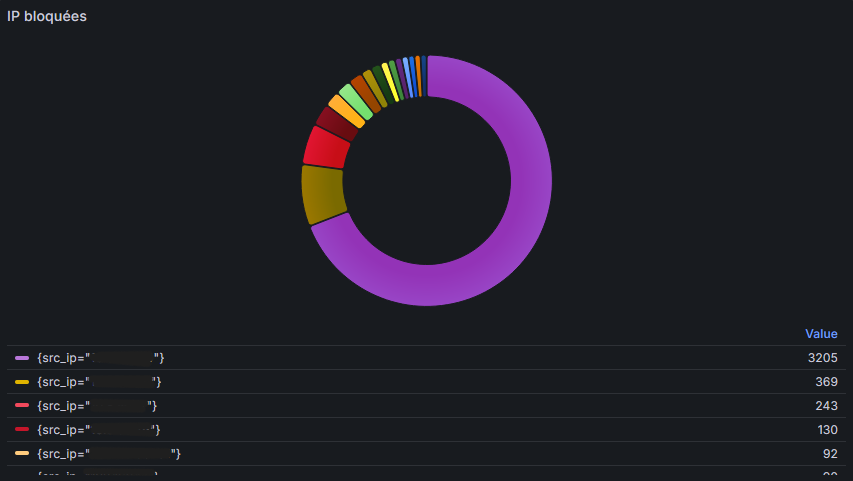
Ensuite je me suis lancé dans la création de dashboard en mode graphique pour avoir quelque chose d'un peu plus visuel. Ici avec les adresses IP sources et les ports sources les plus bloqués.
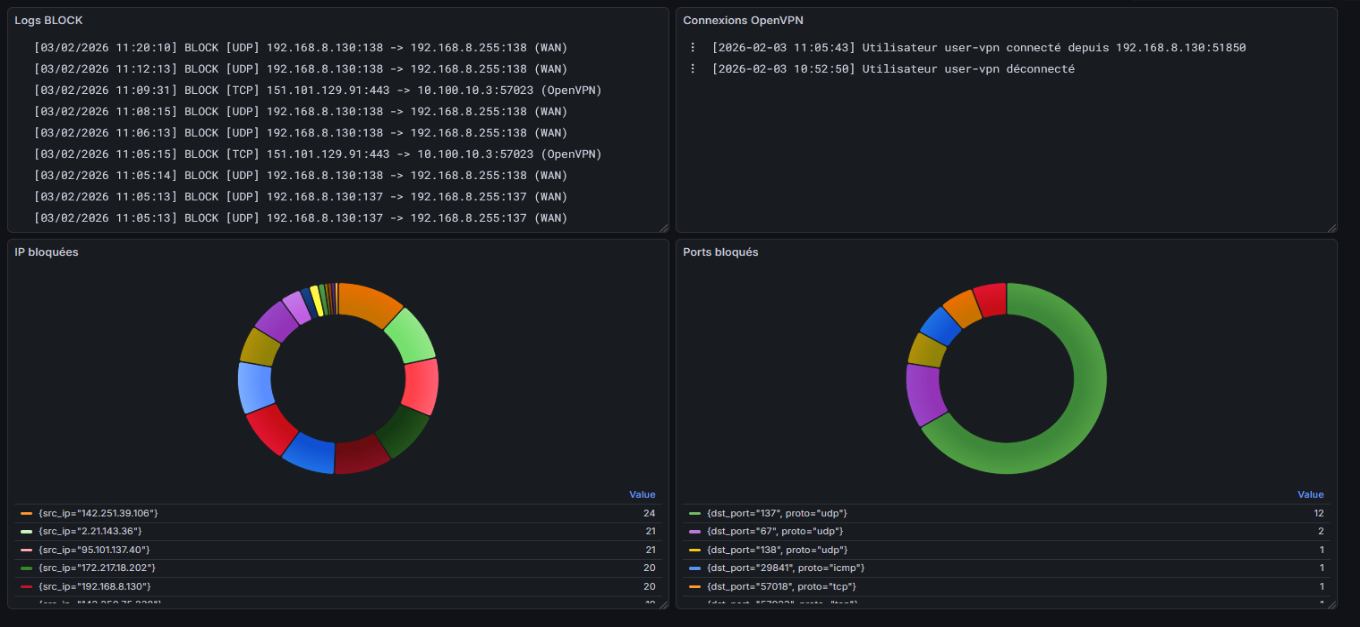
Une fois que j'avais finis mes expérimentations sur mon lab de VM locales il fallait que je mette tout ça en production sur le vrai pare-feu de Innlog.
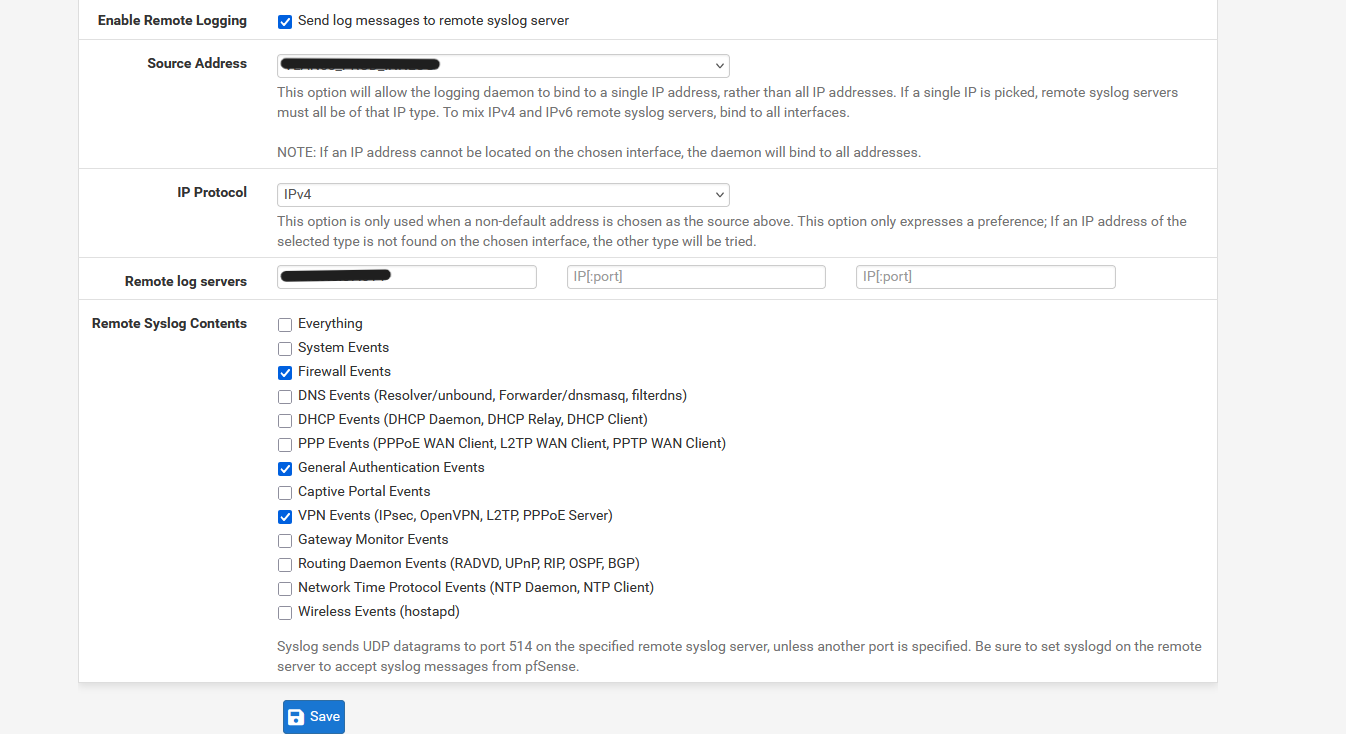
Tout d'abord en configurant le pfsense pour qu'il envoie ses logs via rsyslog.
En faisant remonter le bon label pfsense du fichier de logs via Alloy.
Et ensuite en mettant les bons LogQL j'ai fait un dashboard pour les flux bloqués, les connexions à l'interface web, les connexions et déconnexions au SSH du pare-feu, et au connexions OpenVPN.
Pour les graphiques je n'ai fait que les IP les plus bloquées car pour les ports, il y en avait tellement que le dashboard ne se mettait pas à jour et ne récupérait pas les informations. Avec le message d'erreur suivant :

Cluster Kubernetes et MKS
En fin de semaine, j'ai participé à une réunion DevOps où le sujet principal tournait autour des clusters Kubernetes qui était un sujet totalement inconnu pour moi sauf de nom, j'ai donc pu comprendre les principales différences avec Docker et comment Innlog utilise Kubernetes pour leur infrastructure as code (IaC).
Déjà dans un premier temps la principal différences avec Docker est que Docker est un conteneur donc une seule image à la fois et Kubernetes est un orchestrateur de conteneur c’est à dire que Kubernetes lui va s’occuper de gérer et faire communiquer des dizaines voir des centaines de conteneurs à la fois.
Il y a tout un jargon propre à Kubernetes qui est très important à comprendre pour être le plus familier possible avec cette technologie.
Les composants cerveau du cluster :
-
Control Plane
sont l’ensemble des services qui dirigent le cluster. Dans l’offre MKS de chez OVH cloud, cette partie est infogérée par OVH directement.
-
API Server
C’est l’API qui reçoit les fichiers YAML des conteneurs.
-
ETCD
L’ETCD est un des points d'ancrage d’un cluster Kubernetes, c’est une base de données qui stocke toutes les configurations de tout ce qui tourne dans le cluster.
-
Scheduler
C’est un algorithme qui permet de gérer l’espace de stockage de votre cluster, c’est lui va décider sur quel serveur (Node) placer les conteneurs.
Les objects qui se trouvent dans un cluster :
-
Les Pods
c’est la plus petite unité d’un cluster, il contient un ou plusieurs conteneurs et ces mêmes conteneurs partagent la même adresse IP et le même stockage local.
-
Deployement
Le Deployement est un objet qui définit comment l’application tourne, la version des images Docker, les mises à jour automatiques etc.
-
ReplicaSet
le ReplicaSet est une stratégie de déploiement dans Kubernetes qui va nommer les pods aléatoirement si le pod redémarre, l’ordre de démarrage est en parallèle donc tous les pods en même temps, les volumes des conteneurs sont souvent partagé et les IP sont changeantes.
-
StatefulSet
le StatefulSet est une autre stratégie de déploiement qui est beaucoup plus stable avec une nomenclature des conteneur qui est définit, un ordre de démarrage séquentiel, des volumes individuel et des IP stables.
-
Ingress
ingress est la couche de routage HTTP, les règles de routage étant définies dans un fichier YAML comme tous les éléments de configuration d’un cluster kubernetes, il utilise l’ingress controller qui agit souvent comme un reverse proxy ou un Load balancer à l’image de nginx, traefik ou HAproxy.
Les stratégies de stockage :
-
Les PV
sont les ressources physiques du cluster.
-
Les PVC (Persistent Volume Controller)
les PVC correspondent à des requêtes des conteneurs pour demander un espace de stockage pour le volume du conteneur.
Si l'on devait mettre tous ces outils dans un schéma ça donnerait quelque chose comme ça :
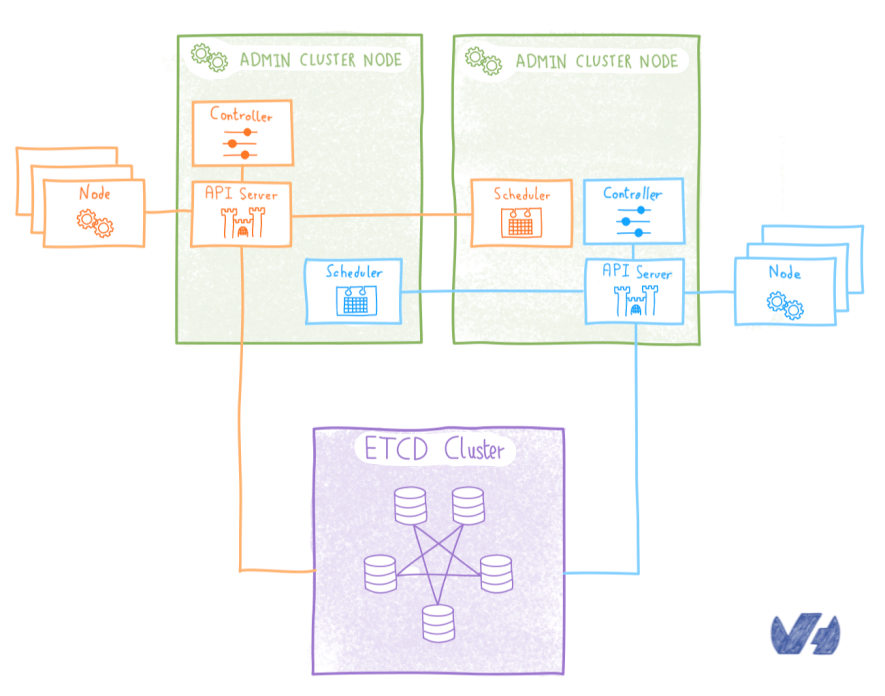
Ici on voit bien que les ETCD sont redondés dans l’infrastructure ce qui est très important étant donné qu’ils contiennent toutes les configurations du cluster.
Dans la situation d'Innlog c'est un peu plus différent que ça, en effet l'entreprise a fait le choix d'héberger son infrastructure Kubernetes chez OVH avec l'offre MKS (Managed Kubernetes as a Service). Avec cette offre chez OVH, une bonne partie de l'infrastructure est infogérée par OVH directement.
Avec une infrastructure MKS, un cluster Kubernetes ressemble à ça.
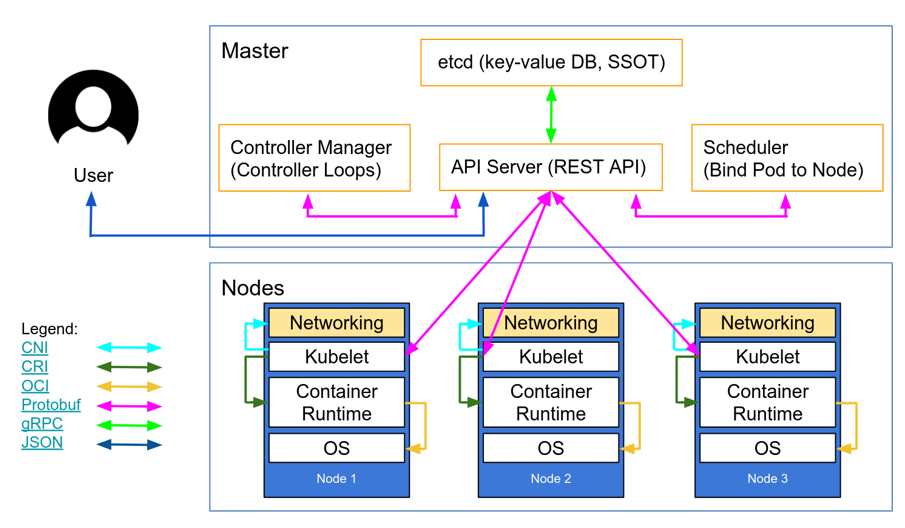
Détail du schéma :
Encadrement Master :
Dans le cas d'une infrastructure MKS, tout les composants dans la partie Master du schéma est géré par OVH et est redondé plusieurs fois, comme c’est le cas pour l’ETCD par exemple.
-
API Server
Dans ce cas, elle joue le rôle de cœur du cluster, toutes les requêtes et toutes les commandes arrivent sur cette API.
-
ETCD
Dans ce cas, il joue le même rôle que dans la définition précédente. SSOT veut dire Single Source of Truth, c’est pour spécifier que si une information n’est pas dans ETCD, elle n’existe pas pour le cluster.
-
Controller Manager
Lui, joue le rôle de surveillance du cluster via ce qu’on appelle des boucles de contrôle dans l’exemple d’un cluster de 3 pods, s’il en détecte que deux, il demandera la création du troisième.
-
Scheduler
il joue le même rôle que dans la définition précédente également, il va vérifier les ressources disponibles sur les trois Nodes et décider où envoyer les nouveaux pods.
Encadrement Nodes :
Les Nodes sur le schéma représente l'architecture physique du cluster, c'est ce qu'achète Innlog chez OVH pour faire tourner leurs applications.
-
Kubelet
Dans ce cas, elle joue le rôle de cœur du cluster, toutes les requêtes et toutes les commandes arrivent sur cette API.
-
Container Runtime
Kubelet reçoit les ordres de l’API Server et s’assure que les conteneurs tournent bien sur sa machine (cycle de vie des conteneurs, fait des rapports qu’il envoie au reste du cluster et vérifie la santé des conteneurs).
-
Networking
c’est là que se passe l’attribution des IP aux pods et la communication entre eux
-
OS
c’est le système d’exploitation (très souvent une version légère de Linux)
Il y a également toute une liste de protocoles qu'utilise le cluster pour son bon fonctionnement.
-
CNI (Container Network Interface)
Quand un pod est créé dans le cluster, le Kubelet appelle ce plugin pour avoir une adresse IP et le connecter au cluster.
-
CRI (Container Runtime Interface)
c’est ce qui permet la communication entre le Kubelet et le moteur de conteneur, par exemple pour utiliser Docker ou containerd.
-
OCI (Open Container Initiative)
C’est ce qu’on appelle un standard de format et il permet en fait qu’un conteneur créé sur ton pc fonctionnera partout ailleurs.
-
Protobuf
C’est un format plus rapide et léger que le JSON pour la communication massive entre le Master et les Nodes.
-
gRPC
C’est le format de communication entre ETCD et l’API Server ce qui permet une communication ultra rapide pour les écriture de nouvelle configuration par exemple.
-
JSON
C’est le format standard, c’est que l’utilisateur envoie via ses fichiers YAML/JSON ou ce qui s’affiche dans le dashboard etc.
Comment tout cela fonctionne en terme de flux ?
L’utilisateur envoie son fichier YAML/JSON à l’API Server.
L’API Server enregistre la demande dans ETCD via gRPC.
Le Controller Manager détecte le nouveau déploiement.
Le Scheduler choisit un Node disponible pour le conteneur.
L’API Server envoie l’ordre au Kubelet du Node (via Protobuf).
Le Kubelet demande au Container Runtime (CRI) de lancer le conteneur.
Le Runtime utilise les standards OCI pour créer le processus OS.
Le Networking via CNI connecte le conteneur au reste du cluster.
Déploiement d'un LAB CrowdSec et attaque DoS
Après en avoir terminé avec les clusters Kubernetes, je me suis lancé dans la création d'un LAB, par le biais de VM locales, cette fois-ci plus orienté cybersécurité, afin d’expérimenter les attaques DoS et la protection via le pare-feu CrowdSec.
Tout d’abord ce lab était pour apprendre les différences qu’il y a entre un simple fail2ban qui est déjà efficace à son échelle et un CrowdSec qui est beaucoup plus complet et surtout comment peut être lancer une attaque DoS et non pas DDoS dans ce cas car évidemment je ne dispose pas d'assez de moyen pour réaliser ce genre d’attaque grand échelle.
En tout cas j'ai commencé par créer mes VM et d'installer un simple serveur apache2 afin de l'attaquer depuis la machine Kali Linux.

Ces manipulations doivent être réalisées uniquement dans un cadre professionnel, scolaire ou sur un environnement de test personnel. Elles ne doivent en aucun cas être effectuées sur un réseau ou un système qui ne vous appartient pas ou sans autorisation. Cela peut entraîner des sanctions, comme des amendes ou des peines de prison.
Pour commencer l'attaque j'ai d'abord lancé un simple nmap sur le réseau du lab avec la commande suivant qui permet de découvrir les hôtes présents sur le réseau.
nmap -sn <adresse réseau>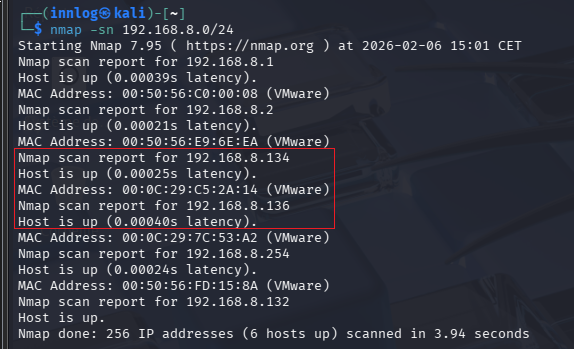
Ici on voit que les deux machines présentes sur le réseau sont détectées, la machine où sera installer le CrowdSec (192.168.8.134) et la machine cible (192.168.8.136). Une fois le premier nmap réalisé, on fera une deuxième commande cette fois-ci pour détecter les ports ouverts sur les deux machines.
nmap -p- <adresse IP>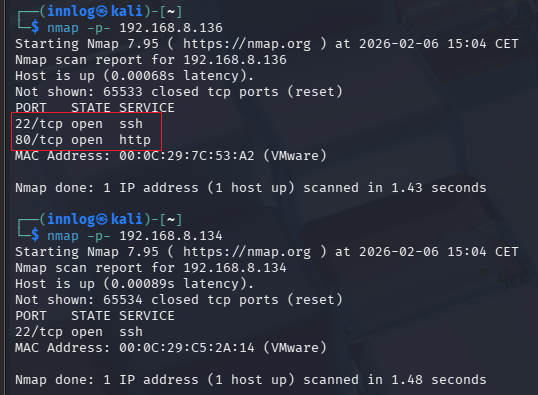
Sur cette capture d'écran on voit que sur la machine cible les ports 22 (SSH) et 80 (HTTP) sont ouverts du fait du serveur web apache.
Pour lancer l'attaque, j'utilise un outil qui s'appelle WRK, il n'est pas natif sous Kali mais peut rapidement être installé via apt. Cet outil fonctionne avec plusieurs options, les plus imprtantes étant :
-
-c
c’est le nombre de connexions HTTP qui resteront ouvertes le temps de l’attaque.
-
-d
c’est le temps que durera l’attaque.
-
-t
ce paramètre est extrêmement important car c’est le nombre de threads utilisés par le processeur pour réaliser l’attaque, plus le nombre de threads sera élevé plus l’attaque sera brutale (mais la machine doit suivre évidemment). La brutalité de l’attaque dépend également du paramètre -c car plus il y a de connexion HTTP ouvertes moins la machine cible à de chance de supporter l’attaque.
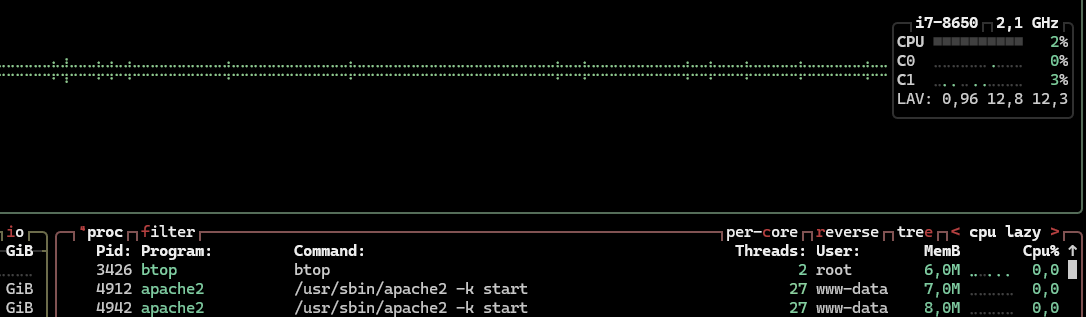
Pour suivre le déroulement de l'attaque j'ai utilisé, sur la machine cible btop, un petit utilitaire en TUI (Terminal User Interface) que j'ai également installé sur mon raspberry PI et qui sert à suivre la charge CPU, la RAM, la bande passante etc. C'est pareil que top ou encore htop mais en plus moderne.
Voici l'état du CPU avant l'attaque :
Et une fois l'attaque lancée
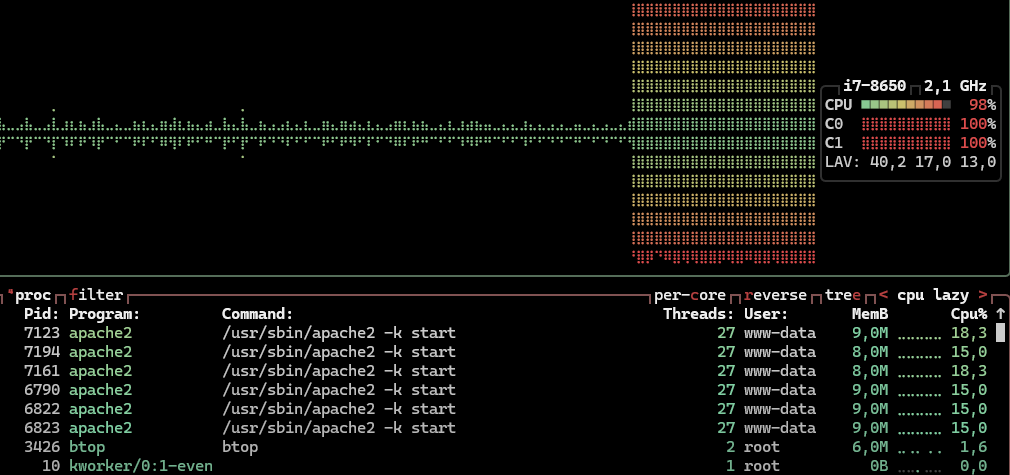
Ici on voit très bien que le CPU est en sueur et que les processus d’apache le sont aussi. L’attaque à donc “réussi”, je met entre guillemet car il en faut plus que ça pour faire tomber un serveur web et l’accès à la page par défaut d’apache est encore disponible mais on voit bien quand même que la machine subit une attaque et qu’avec une plus grosse machine et un plus gros CPU sur la machine attaquante, le serveur ne ferait pas long feu, et encore pire si plusieurs machines s’y mettent par exemple avec des botnet, là ça deviendrait une attaque DDoS et non plus une DoS.
La prochaine étape sera d'installer le CrowdSec sur la machine qui jouera le rôle de pare-feu et d'installer l'agent sur la machine cible afin qu'elle soit protéger et qu'on voit les blocages dans le CrowdSec.
À la suite de l'attaque réalisée la semaine précédente, j'ai commencé à installer CrowdSec sur mes machines.
Avec la commande cscli collections list, on peut voir que CrowdSec crée
des collections, qui sont des fichiers d'analyse de logs créés par défaut, car CrowdSec détecte automatiquement les services installés sur la machine.
Pour que la machine distante soit protégée, il faut évidemment installer CrowdSec sur celle-ci mais aussi l'enregistrer auprès du serveur qui va jouer le rôle de protection.

Et faire approuver la demande d'enregistrement de la machine sur le CrowdSec.

Une fois que la machine est enregistrée auprès de notre serveur CrowdSec, il y a un petit détail qu'il faut corriger pour le bien du LAB. Sur les deux machines
un fichier de whitelist est créé et ce fichier par défaut autorise le réseau 192.168.0.0/16 dont fait partie les machines de notre LAB, donc si on veut
vraiment un blocage il faut commenter ce CIDR la dans le fichier /etc/crowdsec/parsers/s02-enrich/whitelists.yaml

À ce stade là du LAB, le CrowdSec détecte les attaques mais ne les bloque pas. Pour ça il faut installer ce qu'on appelle des bouncers, ce sont des sortes de modules/plugins qui s'ajoute à votre CrowdSec, et celui que l'on va installer est le cs-bouncer-firewall qui va nous permettre de bloquer les IP malveillantes.
Il faudra d'abord l'installer sur les deux machines. Sur le serveur CrowdSec, nous allons générer une clé API que l'on mettra dans le fichier de configuration du bouncer de la victime pour que les logs soient communiqués au pare-feu afin qu'il bloque les comportements malveillants.
Commande pour générer la clé API :
sudo cscli bouncers add ApacheServerUne fois la clé API générée, notre machine victime apparaîtra dans la bouncers list

Évidemment dans le fichier de configuration global de CrowdSec /etc/crowdsec/config.yaml, il faudra faire écouter l'API sur 0.0.0.0
car par défaut elle écoute sur localhost, 127.0.0.1

Du côté de la machine victime, le bouncers étant installé, il faudra aller dans le fichier de configuration de ce dernier /etc/crowdsec/bouncers/crowdsec-firewall-bouncer.yaml
et y mettre la clé API précedemment générée et l'URL sur lequel la machine doit pointer.

Pour vérifier que la machine victime contacte bien l'API du serveur CrowdSec on peut essayer un curl
curl -v -H "X-Api-Key : <votre clé API> <le endpoint de l'API>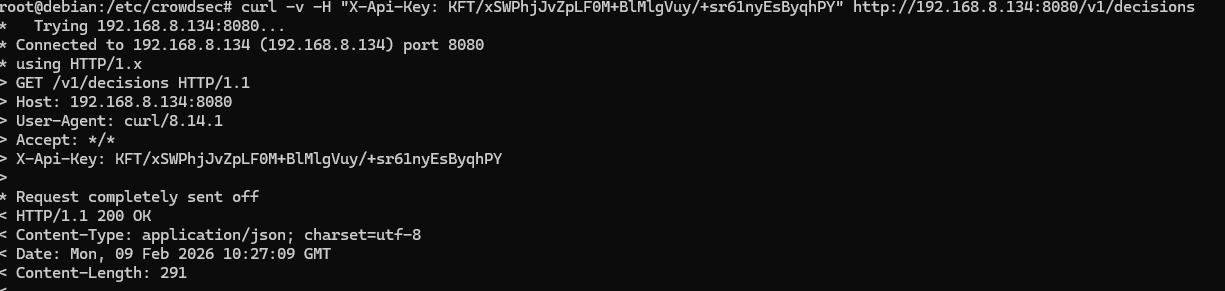
Une fois que les deux machines communiquent on peut essayer de lancer une attaque via WRK et voir comment le CrowdSec réagi.
En lançant une attaque via WRK comme la semaine dernière, CrowdSec ne détecte rien et donc ne bloque pas, c’est en fait tout à fait normal. Les paquets qu’envoi WRK sont des HTTP 200 OK ce qui fait qu’il n’y a pas d’erreur juste beaucoup de requêtes à la fois mais ce n’est pas pris en compte par CrowdSec. Il faudrait donc envoyer des requêtes pour l’instant qui génère des erreurs comme celle-ci par exemple :
for i in {1..50}; do curl -I http://192.168.8.136/fake-page-$i; doneC’est une ligne de bash qui pour une boucle de 1 à 50 faire des curl sur le serveur apache2 de page qui n’existe pas ce qui génère donc des erreurs 404, voyons comment CrowdSec interprète ça.


Ici on voit que des alertes ont été reçues par le CrowdSec, il a donc décidé de bannir cette adresse IP qui est l’IP de ma Kali Linux.
J'ai également fini par réaliser un schéma qui illustre l'architecture de mon attaque.
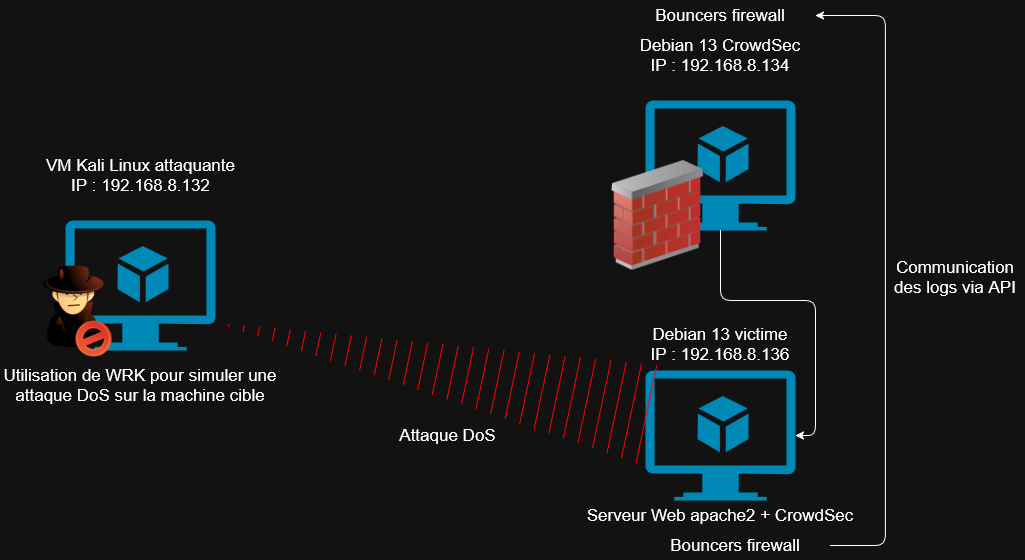
J’ai fini mon LAB, en effet bloquer des attaques via WRK doit surement être possible mais étant donnée que cette attaque n’envoie que des requêtes HTTP 200 OK, c’est très compliqué de pouvoir bloquer ce genre de requête car dans le cas d’une mise en production d’un outil pareil cela voudrait dire que si beaucoup de gens se connectent en même temps sur un site, le serveur va aussi recevoir plusieurs requêtes d’un coup ce qui est plus ou moins équivalent à une attaque WRK mais beaucoup moins violente quand même. Donc dans ce cas ça voudrait dire que tous les clients qui ont fait ces requêtes seront bannis.
Déploiement d'un vault OpenBao
Pour ma dernière mission au sein d'Innlog, j'ai déployé un vault OpenBao. C'est un projet Open Source qui est utilisé dans les infrastructure as code (IaC). Et qui est un fork du Vault de HashiCorp qui lui est passé sous licence propriétaire et donc payante. Il sert notamment à stocker des mots de passe, des secrets, ou encore des informations sensibles.
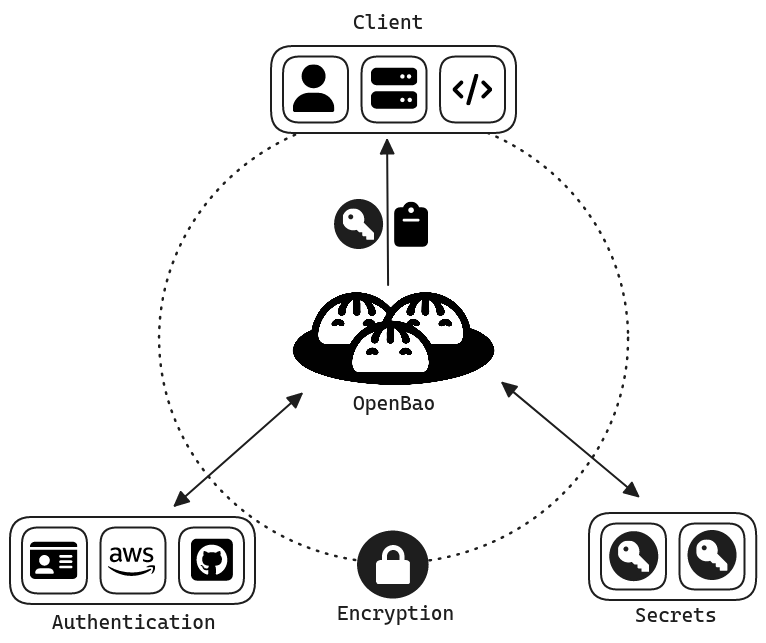
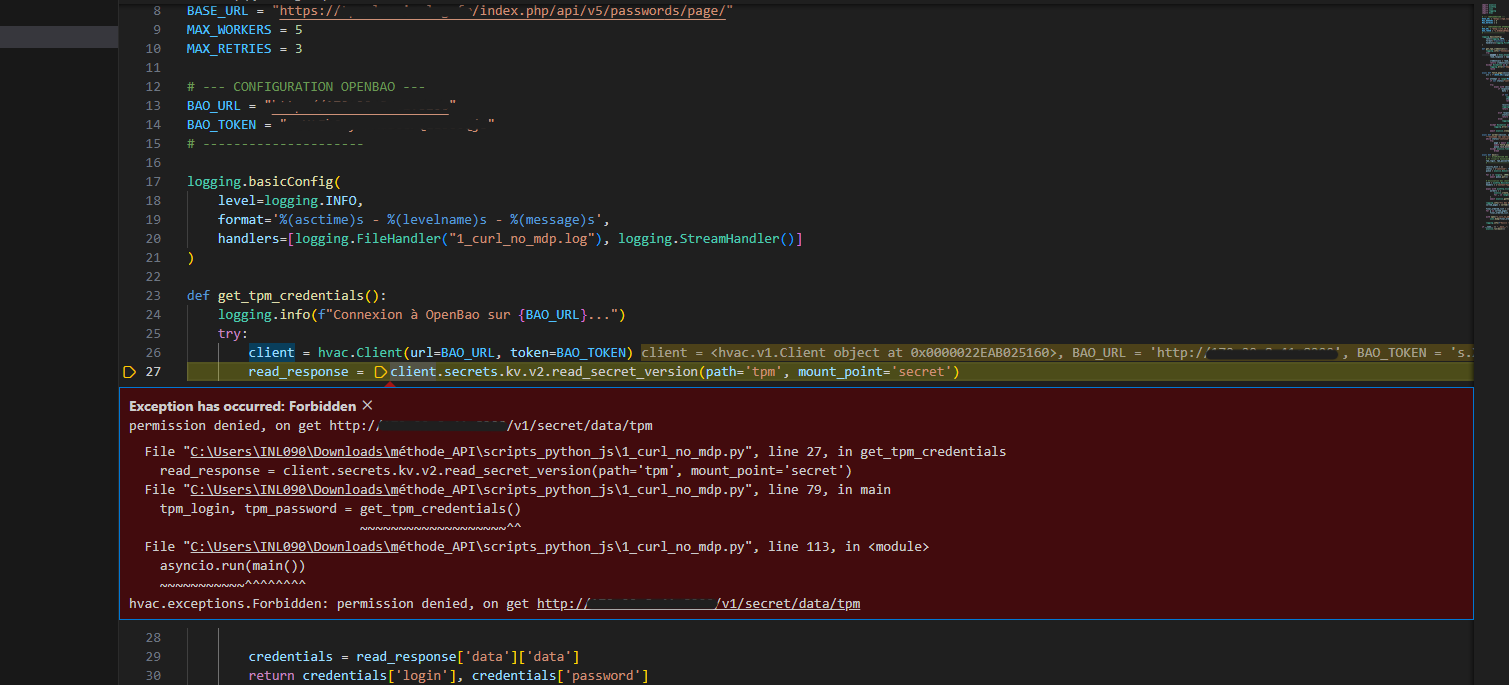
J’ai donc eu l’idée d’utiliser cet outil avec mes scripts python que j’ai utilisés au tout début de mon stage pour récupérer les mots de passe afin de les migrer vers Vaultwarden. Les trois premiers scripts à utiliser font des curl et ont donc besoin de se connecter à l’API de TPM avec le login et le mot de passe et ces données étaient en clair dans le script ce qui niveau sécurité des données n’est pas au top. Ce que je vais faire c’est donc modifier ces scripts afin qu’ils interrogent l’API d’OpenBao pour qu’ils puissent se connecter et effectuer les curl.
Il faut d'abord initialiser le vault
bao operator init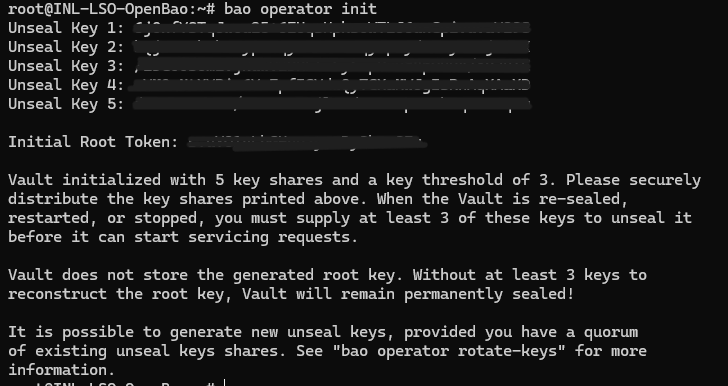
Cette commande va nous donner 5 clés et un token ROOT qui sont extrêmement importants et qu’il ne faut pas perdre car sinon on perd tous les secrets.
Ensuite il faut unseal le vault c'est-à-dire le déverrouiller à l’aide des clés, il faudra rentrer les trois premières clés afin de le déverrouiller jusqu’à ce que
le résumé dise Sealed : false
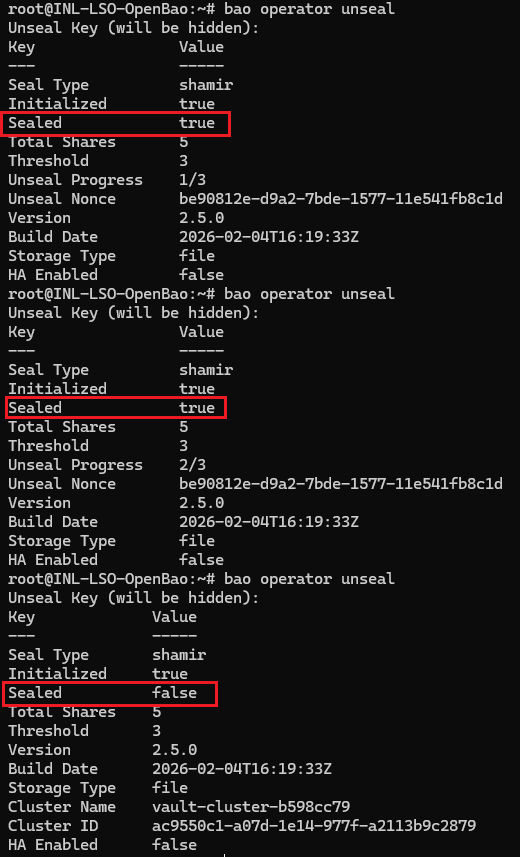
Une fois le coffre déverrouiller, il faut se connecter avec le token ROOT qui nous a précédent été fourni et autoriser le stockage des secrets via la commande bao kv.
bao login <votre token ROOT>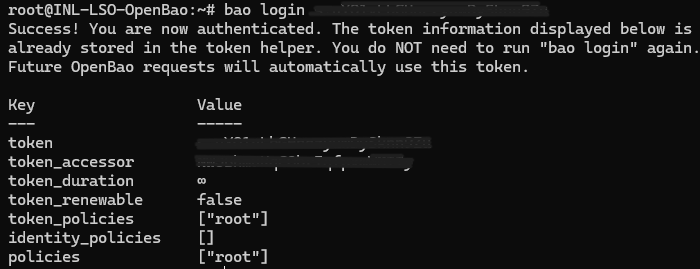
bao secrets enable -path=secret kv-v2
On peut maintenant y stocker des secrets (mots de passe) :
bao kv put secret/<le nom du service> login="<login>" password="<mot de passe>"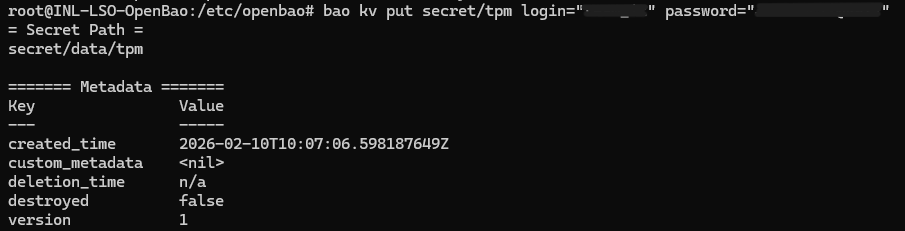
Et vérifier que l'entrée est bien écrite :
bao kv get secret/<le nom du service>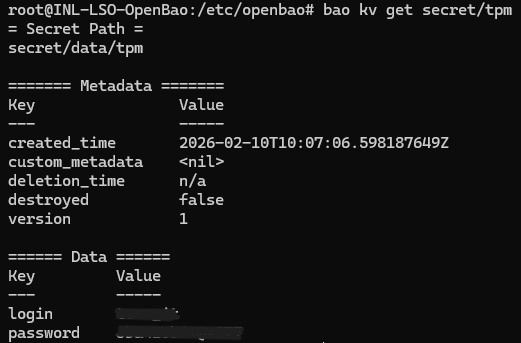
Pour effectuer la modification dans les scripts Python et implémenter cette fonctionnalité, il faut utiliser la bibliothèque HVAC
Petit point les fonctionnalités de la bibliothèque HVAC :
-
HVAC
HVAC pour HashiCorp Vault Api Client sert dans un script python à la gestion de l’authentification par token, username/password ou encore par annuaire LDAP mais également la manipulation des secrets lire, écrire ou mettre à jour. Elle peut aussi servir pour l’administration du serveur en lui-même par exemple en automatisant le déverrouillage du coffre ou encore la gestion des ACL par script.
Il faut ensuite importer la bibliothèque hvac dans le script python faire un bloc de configuration de la connexion et une fonction qui fait le call API et qui va récupérer le login et le mot de passe dans le path secret/tpm
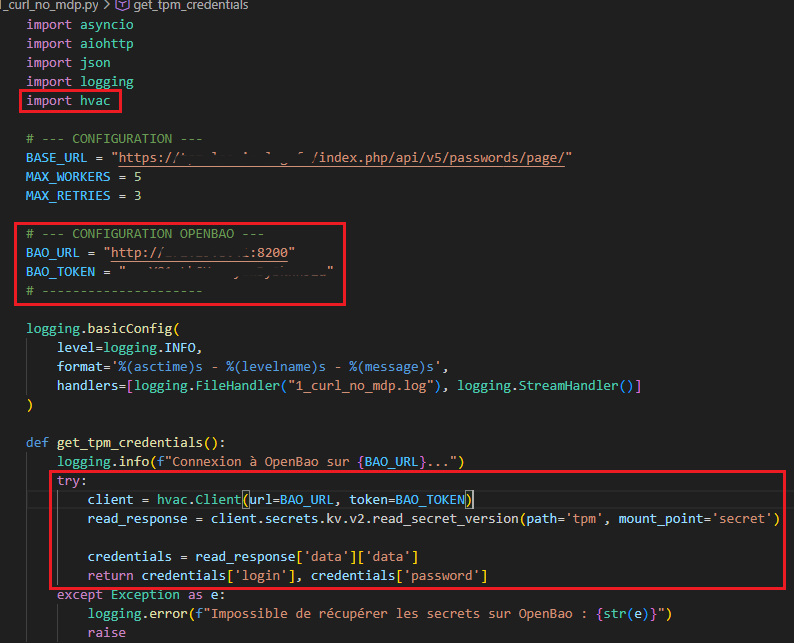
Le problème avec cette première solution est que j'expose le ROOT Token dans le script ce qui encore une fois, niveau sécurité n'est pas optimisé au maximum.
OpenBao dispose également d'une interface web qui permet de gérer plus facilement ses secrets ou ses ACL.
Pour régler le problème du ROOT token, j’ai créé une ACL dans OpenBao qui ne procure que les droits de lecture sur ce secret en
particulier grâce à son path secret/data/tpm et non plus des droits root.
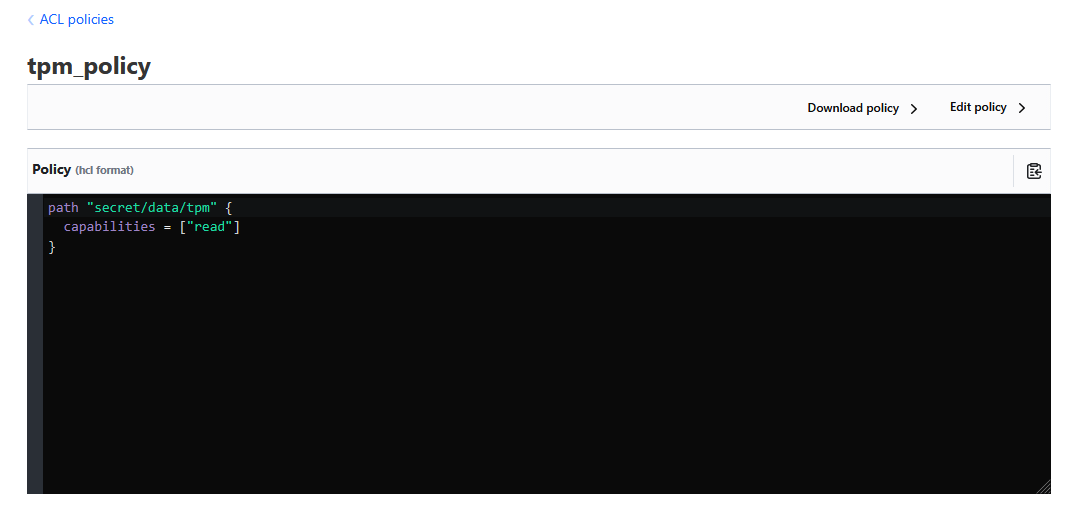
Et ensuite il suffit de taper cette commande pour permettre de générer un token qui applique cette ACL et qui n’est utilisable qu’une seule fois et qui valable pendant 5 minutes.
bao token create -policy=tpm_policy -use-limit=1 -ttl=5mC’est à dire que si l’on relance le script une deuxième fois avec le même token on a une erreur Forbidden.
Pour éviter que la tâche soit trop répétitive j’ai fait un script bash qui précise le serveur ou doit pointer le call API et ensuite qui exécute la commande en ne prenant que la ligne ou se trouve le token grâce à grep et awk vérifie la contenance de la chaîne de caractère et l’affiche.
Car comme me l'a dit un de mes profs un jour : “Si tu dois le faire deux fois, fait un script.”
#!/bin/bash
#Adresse du serveur + port
export BAO_ADDR='http://<ip de la machine OpenBao>:8200'
#Création du token l'utilisation de awk pour ne prendre que le token
TOKEN=$(bao token create -policy=tpm_policy -use-limit=1 -ttl=5m -format=table | grep "^token\s" | awk '{print $2}')
#Affichage du token
if [ -z "$TOKEN" ]; then
echo "Erreur : Impossible de générer le token."
else
echo ""
echo "=== TOKEN à placer dans le script python ==="
echo "$TOKEN"
echo ""
echo "ATTENTION, ce token n'est valable que 5 minutes et utilisable qu'une seule fois à partir de sa création"
echo ""
fiEn fin de semaine je suis revenu sur le coffre Vaultwarden car j’ai invité un autre collègue du service dans le coffre je me suis rendu compte que la permission Afficher les éléments, les mots de passe cachés n’était pas bonne, en effet, cette permission est je pense mal traduite ou implicitement mal expliqué mais elle veut en fait dire que la personne ne peut pas voir les mots de passe il fallait donc remettre les permissions Afficher les éléments seulement, j’ai donc rebalancer le script JavaScript dans la console pour modifier les éléments et la il ne marchait pas. J’ai donc relu mon code JavaScript et il fallait changer quelques petites choses.
Avant cette ligne vérifiait si l’option sélectionnée contenait "Afficher" et "cachés" pour prendre l’option "Afficher les éléments, les mots de passe cachés".

En plus de cette ligne, il y avait un try plus tard dans le code qui prenait l’option qui commençait pas
"Afficher les éléments, les" ce qui encore une fois prenait la bonne option.
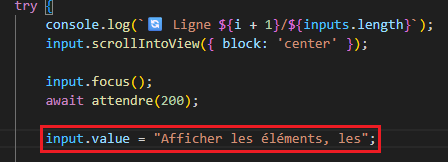
Pour modifier tout ça et repasser les permissions en "Afficher les éléments" il fallait mettre un ! devant le
premier if pour dire au programme si quelque chose contient "Afficher" et ne contient pas "cachés" prend la.

Mais il fallait également modifier le try et enlever le ", les" pour qu’il s’arrête à "Afficher les éléments".
De plus je me suis un peu plus penché sur les différentes permissions qui étaient applicables sur les groupes que l’on crée dans Vaultwarden pour maîtriser l’outil encore un peu plus. Et en faisant des tests je me suis rendu compte des différences subtiles qu’il y avait entre ces différentes permissions.
Dans Vaultwarden quand on crée un groupe dans une organisation il y a cinq permissions différentes que l’on peut appliquer au groupe :
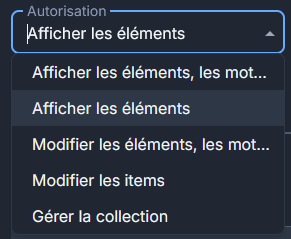
-
Afficher les éléments, les mots de passe cachés
l'utilisateur peut voir les éléments d'une entrée mais pas le mot de passe. Et ne peut pas créer de nouvelles entrées dans les collections de l'organisation.
-
Afficher les éléments
l'utilisateur peut voir les éléments d'une entrée et le mot de passe. Et ne peut pas créer de nouvelles entrées dans les collections de l'organisation.
-
Modifier les éléments, les mots de passe cachés
l'utilisateur peut modifier une entrée mais pas son mot de passe. Et peut créer de nouvelles entrées dans les collections de l'organisation.
-
Modifier les items
l'utilisateur peut modifier une entrée et son mot de passe. Et il peut créer de nouvelles entrées dans les collections de l'organisation.
-
Gérer la collections
l'utilisateur a tous les droits sur les collections, créer, supprimer etc.
Si on mixe ces permissions avec les rôles que l’on peut attribuer aux membres, on se retrouve avec un système similaire à AGDLP.