Stage de deuxième année
Note importante : Cet article ne présente que l'essentiel. Si vous souhaitez entrer dans les détails techniques et comprendre comment j'ai résolu chaque difficulté, ma documentation complète est disponible ci-dessous.
Migration d'une base de données de mots de passe
Lors de mon arrivée chez Innlog, j'ai dû m'approprier rapidement leurs outils internes. L'entreprise utilisait historiquement TPM comme gestionnaire de mots de passe, mais le service IT avait décidé de migrer vers Vaultwarden, une alternative Open Source conçue en Rust. Pour ça j'ai expérimenté deux solutions, exportation de fichiers CSV, l'API de TPM. J'ai passé beaucoup de temps sur la solution des fichiers CSV car TPM n'exporte qu'en CSV. Le coffre fort TPM qu'utilise Innlog contient 6500 entrées qui sont reparties dans plusieurs projets et pour exporter il faut télécharger tous les projets un par un à la main. J'ai donc du automatisé ce processus avec la librairie Python Playwright qui simule un comportement humain sur un site web et qui faisait donc la manipulation d'exportation à ma place. Avec cette technique j'avançais plutôt bien dans le téléchargement des centaines de fichiers CSV mais le script ne marchait plus à partir du moment ou il trouvait un projet qui a le même nom qu'un précédent même si il se trouve dans une autre branche de projets. À partir de ce moment la je me suis penché sur l'API de TPM pour pouvoir tout récuperer beaucoup plus rapidement et ne pas dépendre d'un script python qui fait des manipulations mais d'un script python qui exécute une commande en boucle jusqu'à la fin des entrées de mots de passe ce qui est plus fiable.
Avec les commandes présentes sur la documentation officielle de TPM, un curl, j'ai pu récupérer des fichiers en .json qui contenait des informations intéressantes :
curl -u <login TPM>:"mdp pour se connecter à TPM" -H 'Content-Type:application/json; charset=utf-8' -i https://url_du_tpm/index.php/api/v5/passwords/page/1.json
Ce curl la récupère un .json comme ça :
{
"id": 8980,
"name": "",
"project": {
"id": 1418,
"name": "FTP"
},
"notes_snippet": "",
"tags": "",
"access_info": "",
"username": "",
"email": "",
"has_password": true,
"expiry_date": null,
"expiry_status": 0,
"archived": false,
"project_archived": false,
"favorite": false,
"num_files": 0,
"locked": false,
"locking_type": 0,
"external_sharing": false,
"linked": false,
"updated_on": "2026-01-02 12:18:40"
},
Donc dans ces champs
je n’ai pas le mot de passe en clair, cependant j’ai des id qui vont me permettre de
refaire un curl et d’ajouter cet id à l’url avec ça GET /passwords/ID.json
si je reprend mon curl ça va donner quelque chose comme ça avec l’id du fichier ci
dessus
curl -u <login tpm>:"mdp pour se connecter à tpm" -H 'Content-Type:
application/json; charset=utf-8' -i
https://url_tpm/index.php/api/v5/passwords/8980.json
Ce qui va me donner un json comme ça :
{
"id": 8980,
"name": "",
"project": {
"id": 1418,
"name": "FTP"
},
"tags": "",
"access_info": "",
"username": "",
"email": "",
"password": "",
"expiry_date": null,
"expiry_status": 0,
"notes": "",
"custom_field1": null,
"custom_field2": null,
"custom_field3": null,
"custom_field4": null,
"custom_field5": null,
"custom_field6": null,
"custom_field7": null,
"custom_field8": null,
"custom_field9": null,
"custom_field10": null,
"users_permissions": null,
"groups_permissions": null,
"parents": [
1180,
1217,
1218,
1412,
1418
],
"user_permission": {
"id": 30,
"label": "Manage"
},
"archived": false,
"project_archived": false,
"favorite": false,
"num_files": 0,
"locked": false,
"locking_type": 0,
"locking_request_notify": 0,
"external_sharing": false,
"external_url": null,
"linked": false,
"source_password_id": 0,
"managed_by": {
"id": 2,
"username": "",
"email_address": "",
"name": "",
"role": "IT"
},
"created_on": "2025-12-31 10:53:29",
"created_by": {
"id": 2,
"username": "",
"email_address": "",
"name": "",
"role": "IT"
},
"updated_on": "2026-01-02 12:18:40",
"updated_by": {
"id": 2,
"username": "",
"email_address": "",
"name": "",
"role": "IT"
}
}
cette fois ci avec un champs password qui contient bien le mot de passe en clair Donc pour l’instant j’en suis rendu là, il faudra que je montre mes avancements au responsable IT qui revient lundi pour voir la meilleure solution possible car c’est une manipulation beaucoup plus compliquée que prévu.
Au début de ma deuxième semaine, j'ai essayé d'importer un CSV de test qui venait de KeePassXC et ça marchait il fallait donc que je trouve un moyen de convertir les json que je récuperais de l'API en CSV compatible KeePassXC. J'ai donc fais une checklist des modifications que devait faire le script avec le json.

J'ai donc commencé par le script qui change les "numéros ID" en "mots ID" pour me retrouver avec des .json comme ça, le problème que j'ai eu en faisant ça c'est que certains projets sont vides et n'ont donc pas d'ID et ne peuvent pas conséquent par être changer en mot.
"parents": [
"INNLOG - Commun",
"TESFRI",
"1218",
"1458",
"FTP"
],
Comme solution j'ai donc pensé à faire un script qui récupère lui tous les projets avec leurs noms et leurs ID et qui a comme condition "si je ne trouve pas un nom correspondant à l’ID par exemple 1218 je vais voir dans l’autre fichier .json si je le trouve et si je le trouve je viens le remettre dans le fichier .json de base." Et seulement maintenant je peux passer à la conversion passant du .json au CSV KeePassXC
Après avoir passé le fichier json en CSV, j'avais encore un problème, Vaultwarden a une protection anti-DoS qui fait que je ne peux pas importer un fichier CSV avec des milliers de lignes. Il fallait donc parsé (séparé) le fichier en plusieurs fichiers. À la fin de la journée j'ai finis avec tous ces scripts et ces fichiers CSV que je pouvais enfin importé dans Vaultwarden.
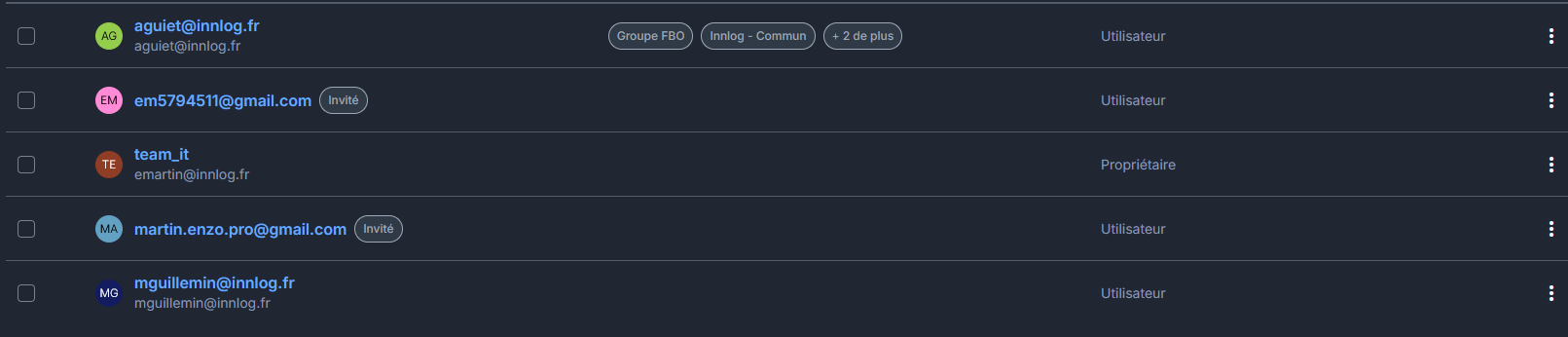
Ensuite dans Vaultwarden il faut créer une organisation pour pouvoir gérer des utilisateurs, des groupes etc.

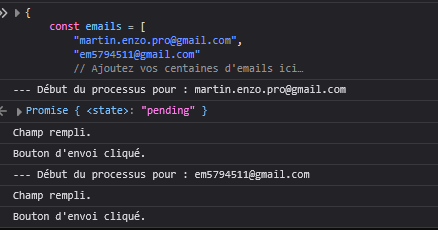
Pour inviter des personnes à utiliser le coffre Innlog il faut les inviter par mails encore une fois un par un, il a donc fallu automatisé ça aussi. Au début j'ai pensé à concaténer plusieurs adresses mails avec des séparateurs comme {} ou , mais ça ne marchait pas. Après ça, j'ai donner à une IA, l'attributs html qui servait à ouvrir un fenêtre modal en JavaScript et l'attribut du bouton "Envoyer" et avec ça j'ai eu un morceau de code JavaScript à balancer dans la console en faisant F12 qui automatisait l'envoie de mail à toutes les adresses mails présentes dans le tableau du morceau de code. Et j'ai essayé avec deux adresses mails qui m'appartiennent pour tester.
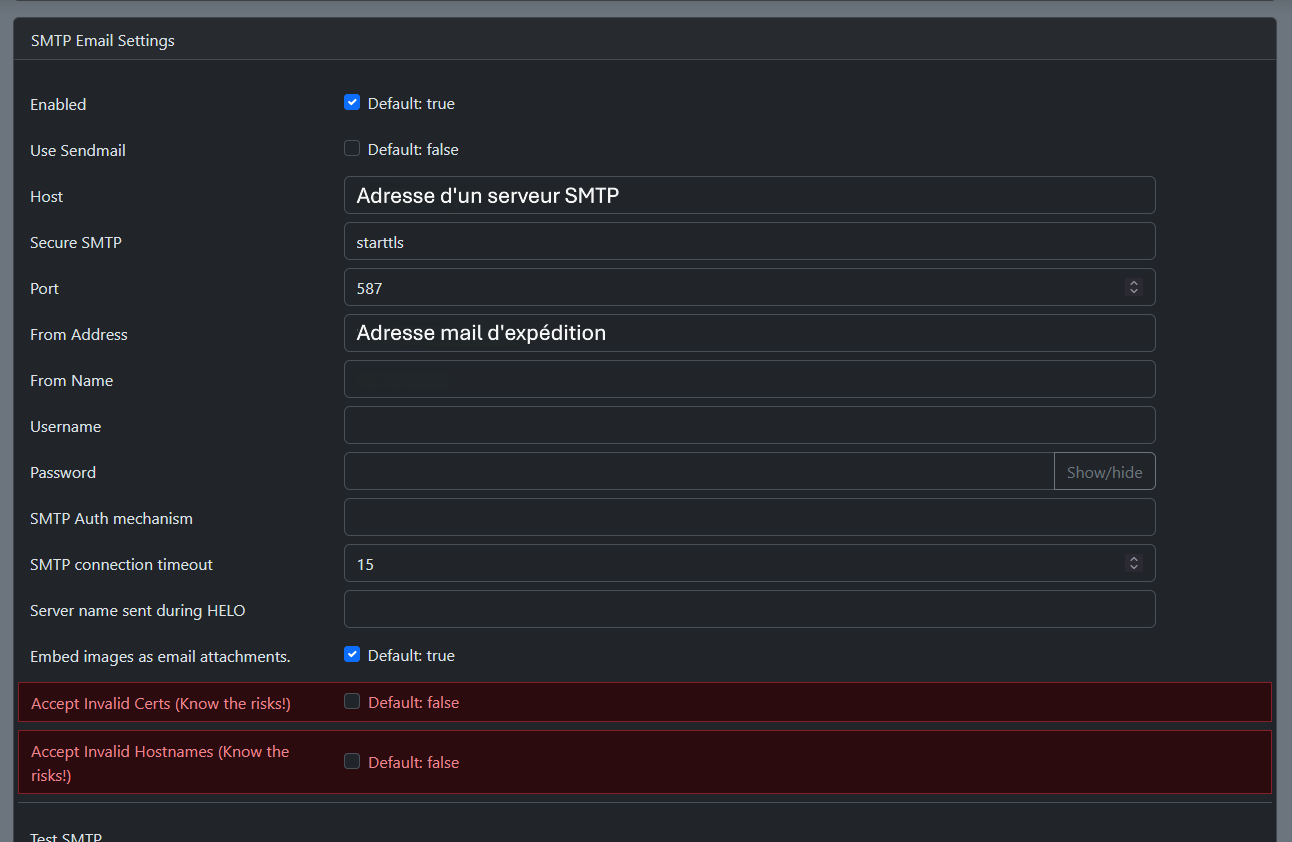
Il fallait aussi configurer un serveur SMTP sur Vaultwarden


Mise en place d'une infrastructure wifi pour un client
À partir de jeudi, la migration vers Vaultwarden étant terminé, j'ai été affecté à une autre mission; mettre en place une infrastructure wifi pour l'un
des gros clients de Innlog. Ce client ayant une infrastructure vieillissante diffusant encore sous le protocole WEP.
Cette nouvelle infrastructure contient 4 switchs Cisco (pour 4 sites distincts) et 17 bornes Unifi U7 outdoor, pour le lab que j'ai mis en place, je n'ai qu'un
seul pare-feu pfSense pour les 4 sites mais dans la réalité, chaque site aura son pare-feu attribuer. Je me suis donc permis de faire le schéma de l'infrastructure sur draw.io
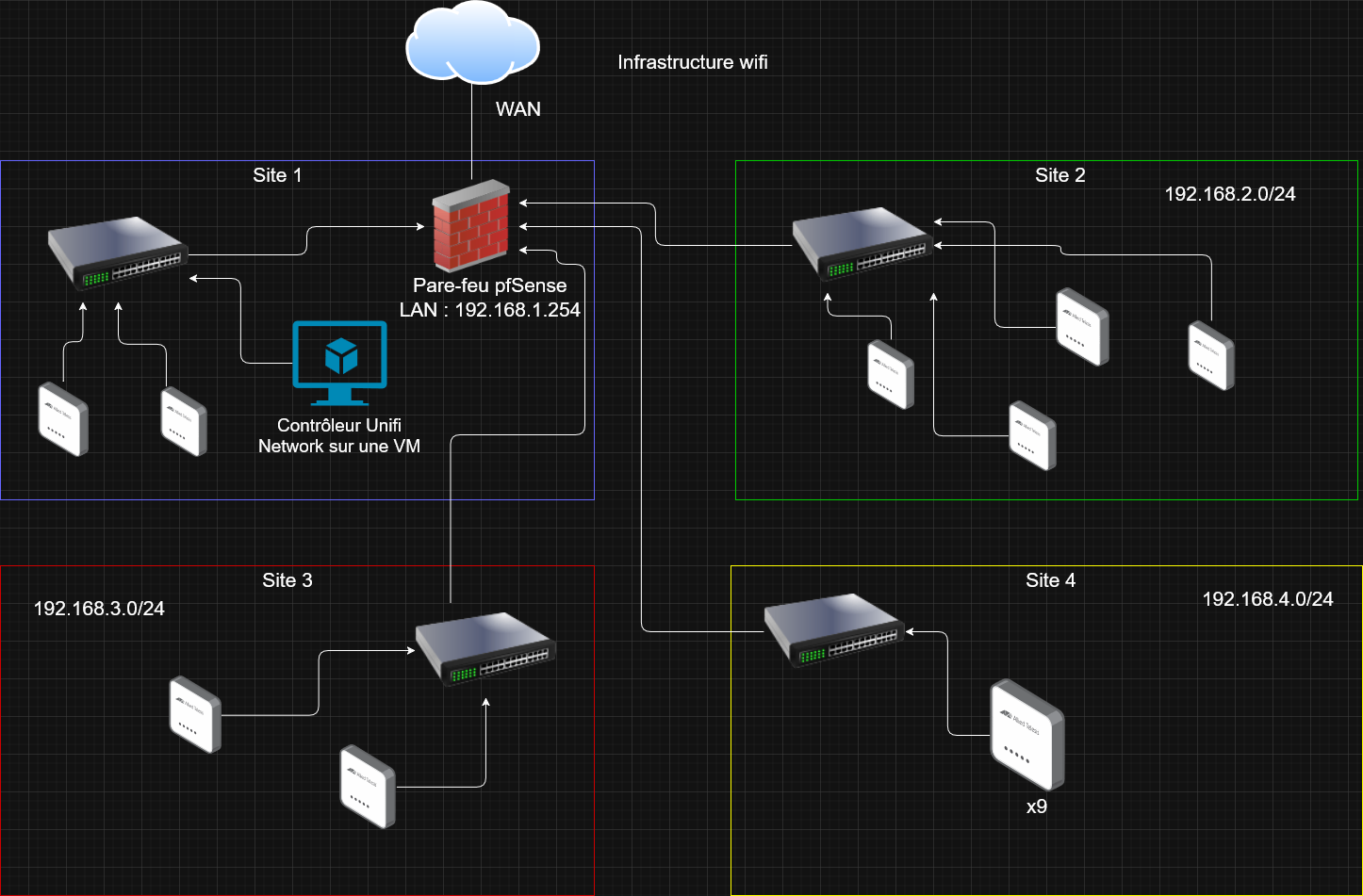
Le contrôleur Unifi étant une machine virtuelle, les bornes devaient toutes remontées sur le contrôleur, les plus faciles étaient celles du premier site car elles sont dans le même réseau que le pare-feu mais ensuite, celles qui étaient dans les autres réseux je devais me connecter en SSH et faire une commande spécifique pour envoyer une invitation au contrôleur pour que qu'il adopte la borne. Je récupère les adresses IP des bornes dans les bails DHCP que distribue le pfSense.
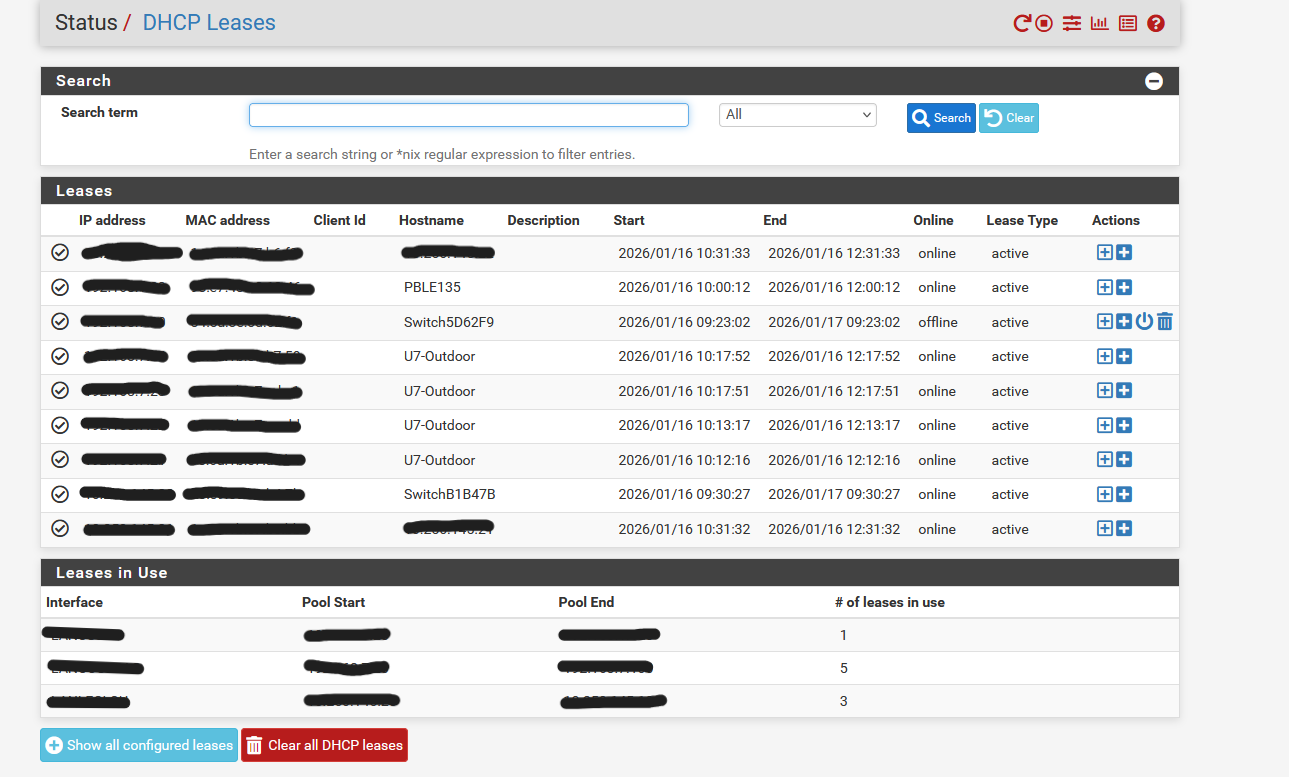
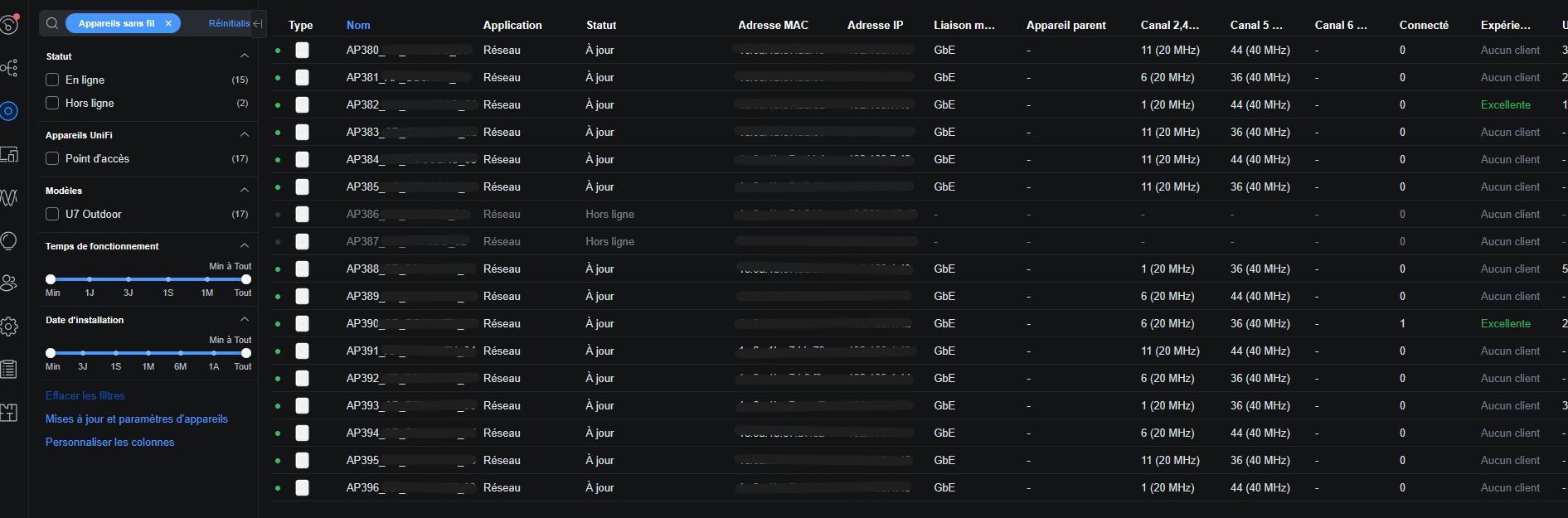
Ça donne ça à la fin, deux bornes étant hors ligne car le pfSense n’a pas assez de ports pour connecter tous les switchs.
Le lundi de la troisième semaine, Anthony le responsable IT à qui j'avais donné un accès pour tester le Vaultwarden a rencontré un problème. En effet il avait accès aux différentes entrées présentes dans le coffre de l'organisation Innlog mais quand il cliquait sur une entrée il ne voyait pas l'URL. J'ai donc regardé et il s'avère que par défaut les utilisateurs invités ont le droit d'Afficher les éléments, hors pour voir les URL dans les entrées, il faut avec les droits Afficher les éléments, les mots de passe cachés.
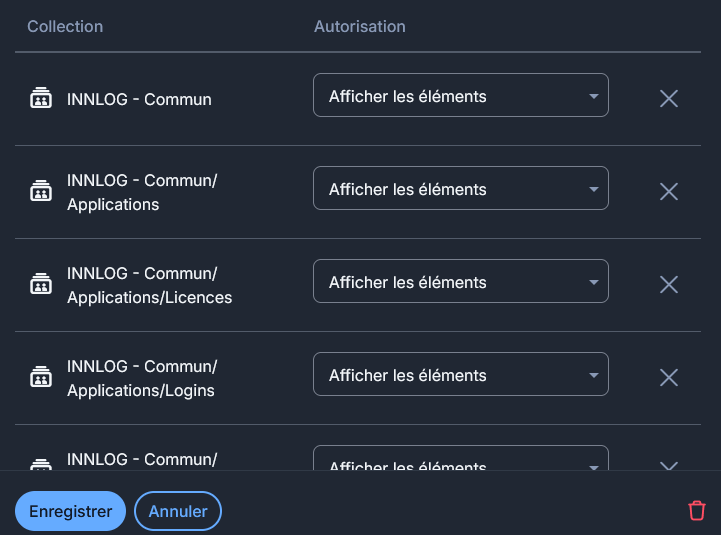
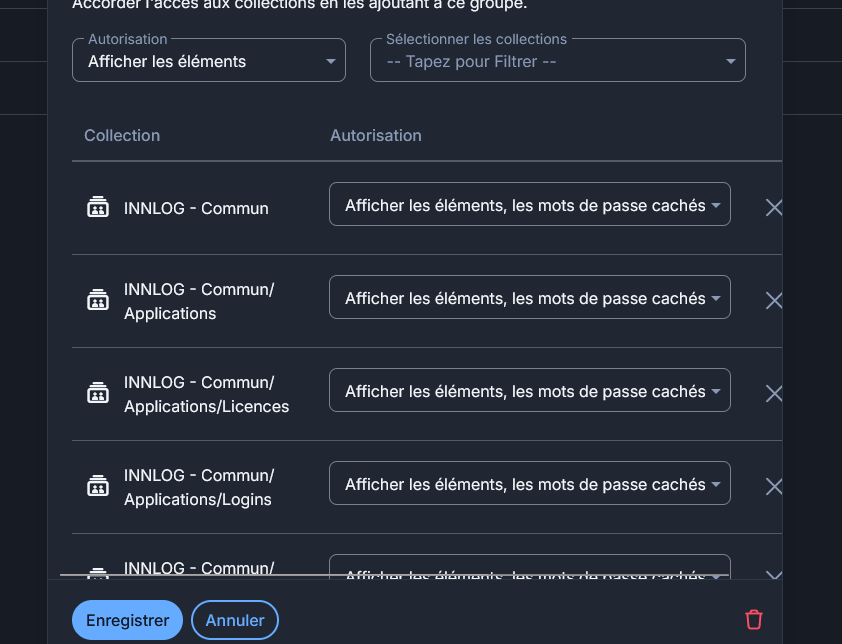
J'ai donc dû automatisé le changement des permissions étant donné qu'il y a plus de 500 dossiers sur lesquels il faut changer ces permissions. Toujours avec un bout de JavaScript que je lance dans la console du navigateur.
Ce qui fait que les permissions ressemblaient toutes à ça à la fin du script.
Ensuite j'ai décidé de faire une documentation sur l'utilisation des scripts Python et JavaScript pour la migration des mots de passe de TPM vers Vaultwarden. En interne Innlog possède un WikiJS qui est un projet Open Source qui peut être auto-hébergé et qui sert à stocké des documentation pour l'ensemble du service sous forme de .md (markdown)
La procédure est disponible ici et sera présente en annexe de ma documentation complète du stage.
Arrivé au jeudi, on avait demandé des plans d'un des sites du client pour lequel j'avais dû faire leur infrastructure wifi pour que dans le logiciel du contrôleur je puisse faire une HeatMap c'est-à-dire un plan avec l'emplacement des bornes wifi pour voir la couverture qu'elles ont.
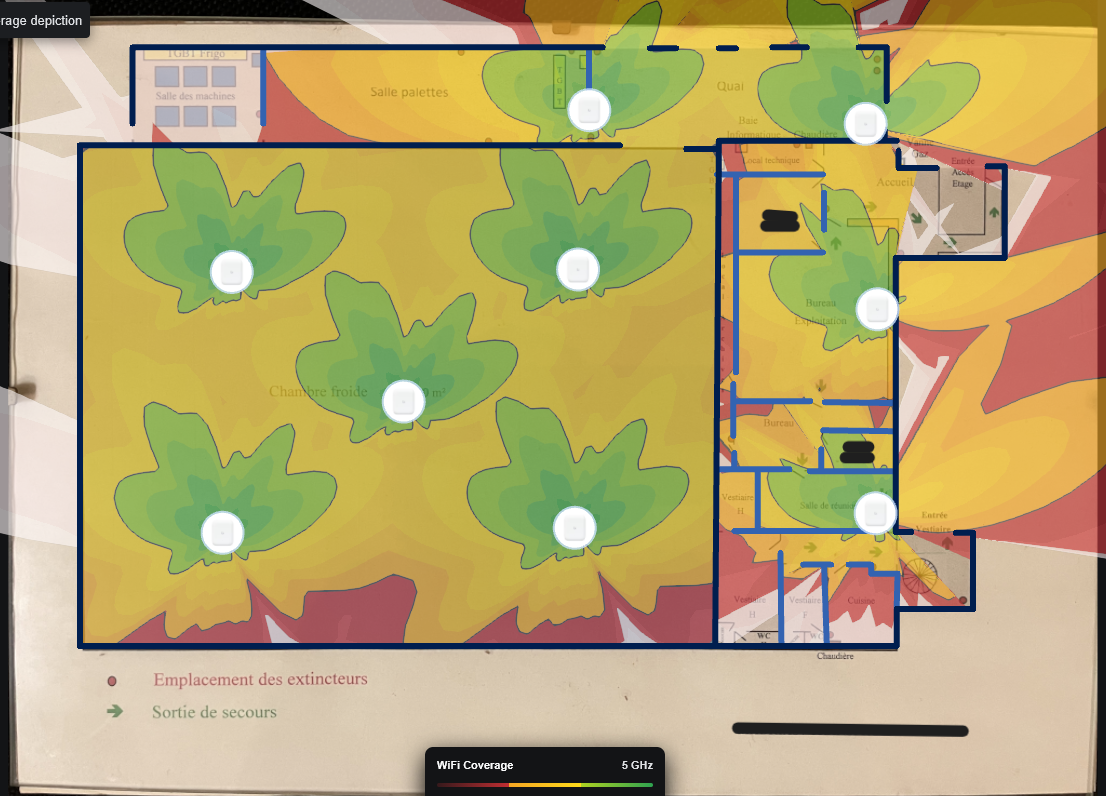
Une fois la HeatMap terminée, on a envoyé le fichier de configuration du contrôleur au client pour qu'il puisse l'importer dans la VM que eux on mis en place.

Déploiement d'une stack Grafana, Alloy et Loki
En fin de semaine, une nouvelle mission m’a été confiée : mettre en place un serveur de centralisation des logs. Dans un premier temps, nous avions envisagé d’utiliser Graylog afin de centraliser les remontées de logs. J’ai donc commencé à me documenter sur la technologie ainsi que sur son installation, mais je me suis rapidement heurté à un problème. Graylog repose sur MongoDB comme moteur de base de données, or à partir de la version 5.0, ce moteur nécessite l’utilisation d’instructions AVX. Cela implique l’utilisation d’un processeur capable de gérer ce type d’instructions. Cependant, ma VM fonctionne sur un hyperviseur équipé d’un processeur d’architecture Nehalem, qui ne supporte pas ces instructions. L’installation de Graylog était donc physiquement impossible.
On a donc décidé de déployer une stack Grafana, Alloy et Loki.
Petit détail de la stack :
-
Grafana
Grafana est l'interface web, elle va utiliser Loki comme source de données pour pouvoir créer des dashboard et faire remonter les logs correctement.
-
Alloy
Alloy est un agent qui va s'occuper d'envoyer les logs d'une machine sur l'API de Loki, il va également s'occuper de parser correctement les logs.
-
Loki
Loki est l'outil qui va stocker les logs, une fois qu'Alloy aura envoyé les logs à Loki il va les stocker et devenir une source de donnée pour Grafana
J'ai d'abord commencé par installer tout ce dont j'avais besoin ;
Une fois que tous les outils étaient installés, j'ai dû aller modifier le fichier de configuration d'Alloy config.alloy afin de mettre les bon blocs pour dans un premier temps afficher les logs SSH dans Grafana.
logging {
level = "info"
}
loki.source.journal "systemd" {
forward_to = [loki.write.default.receiver]
labels = {
job = "journald",
host = "<ip de l’hôte>",
}
}
loki.write "default" {
endpoint {
url = "http://127.0.0.1:3100/loki/api/v1/push"
}
}
logs SSH :
loki.relabel "journal_filter" {
forward_to = [loki.write.default.receiver]
rule {
source_labels = ["__journal__systemd_unit"]
regex = "ssh.service"
target_label = "job"
replacement = "ssh"
}
}
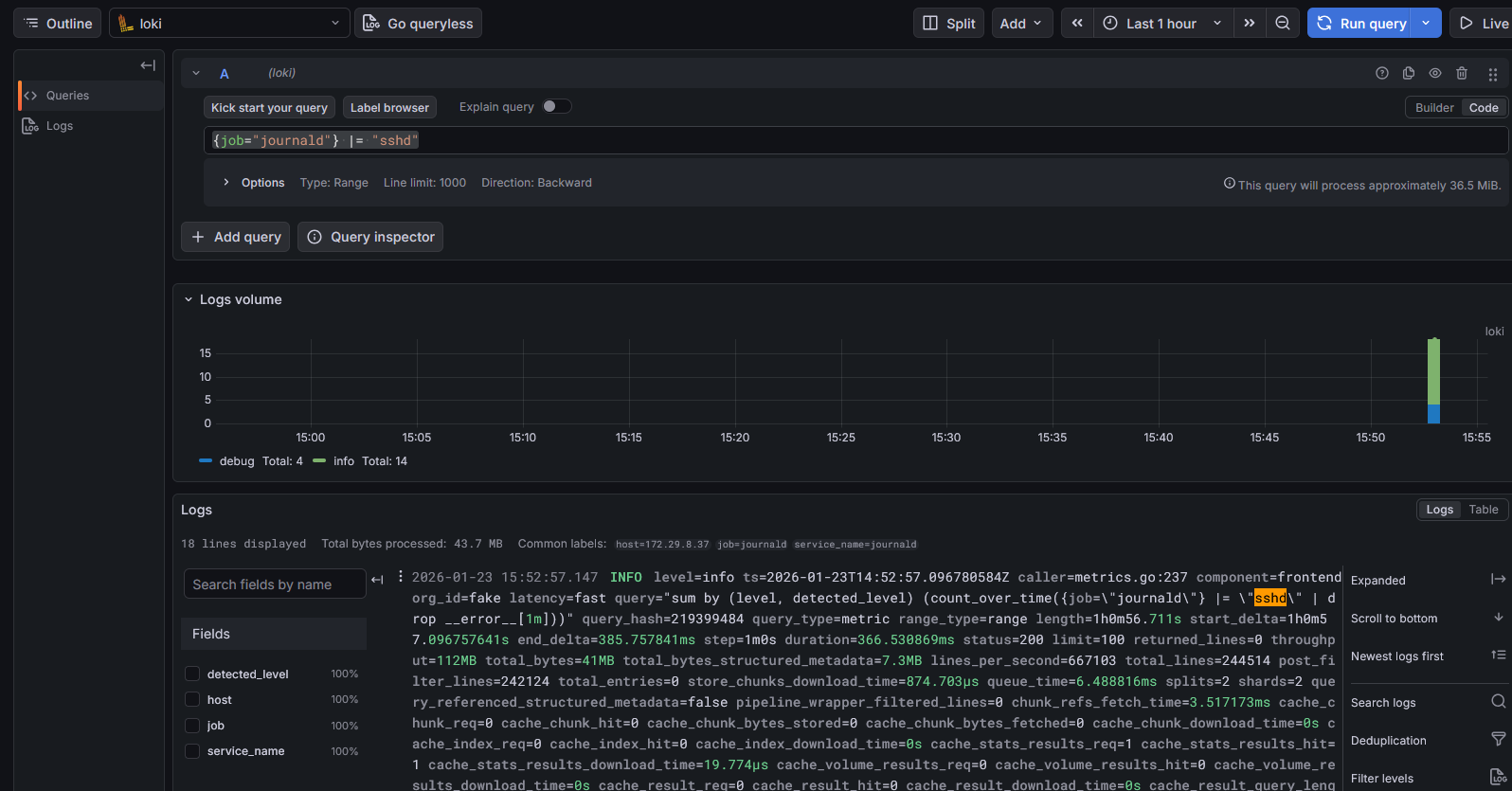
Après avoir modifié le fichier de config il faut ajouter Loki en tant que source de données dans Grafana pour pouvoir faire remonter les logs SSH.
Après ça j'ai décidé d'installer Prometheus pour faire remonter des métriques systèmes comme la charge CPU, la RAM, la bande passante etc.
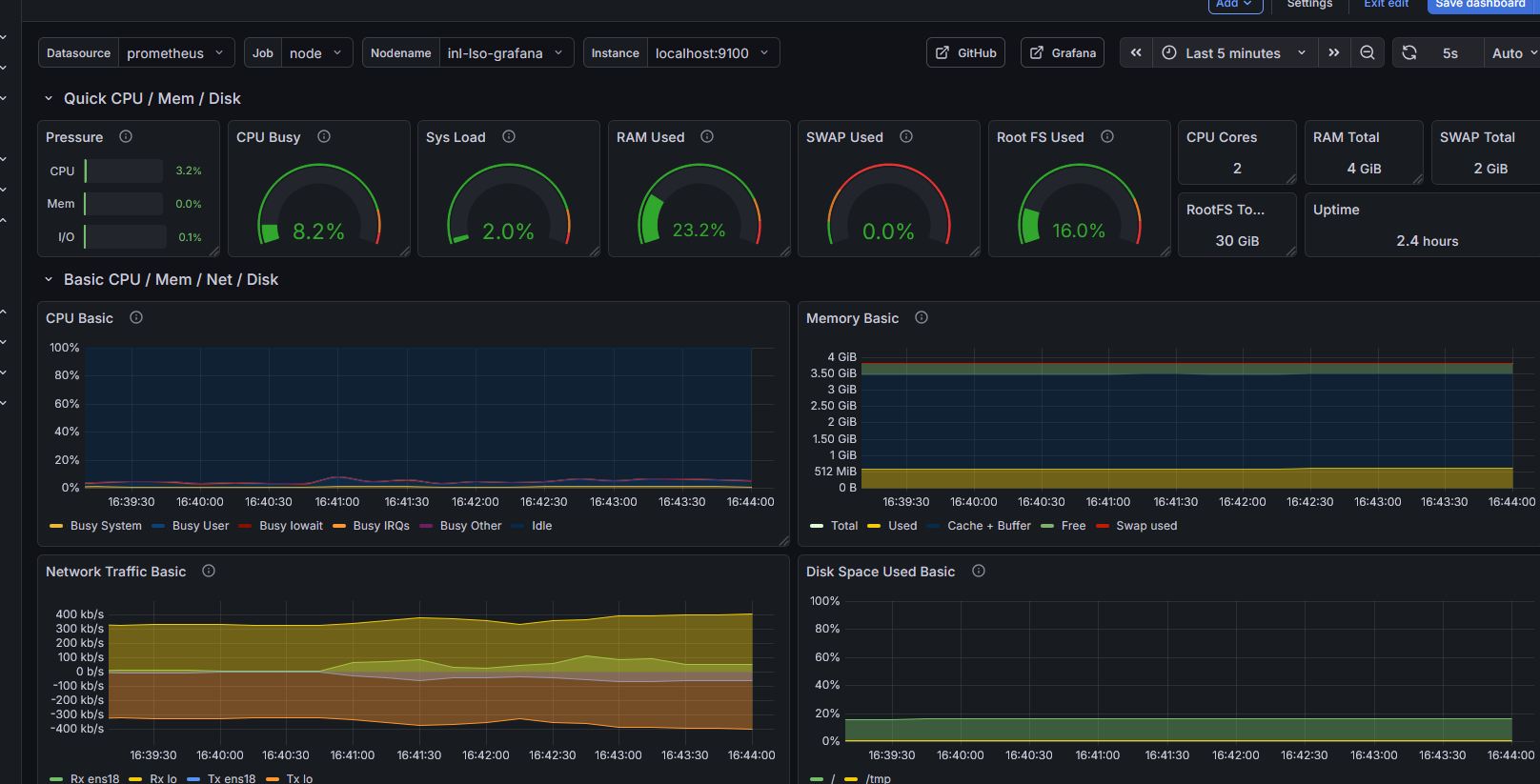
Enfin, il fallait trouver les bons LogQL pour bien parser les logs SSH pour que ce soit plus lisible et faire remonter les informations que l'on veut, une sorte de filtre.